
この記事は音声でもお聞きいただけます。 ※生成AIによるBeta版機能です。
製造業や科学技術の分野においてここ数年でDXの進展やマテリアルズインフォマティクス(MI)の浸透など、AIを含む情報技術の活用がかなり進んできました。しかし、DXによって知見が体系的にデータ化されたが活用の仕方がわからない、MIでいい特性を持つ材料が見つかったが合成できないなど、データからの価値創出とのギャップがある例がまだまだ少なくありません。本記事では、製造業において、データを活用し実際にいいものを効率よく作る「プロセスインフォマティクス」を解説します。
まず第一章ではプロセスインフォマティクス(PI)とは何かをざっくりと説明し、続いて第二章でPIを理解するための基礎技術を説明します。機械学習や数理最適化を勉強したことがある方は第二章を飛ばしてもらって構いません。第三章ではPIを使ってできること、第四章でその事例紹介、第五章ではPIを成功させる鍵について解説します。最後にプロセスインフォマティクスに専業で取り組むプレイヤーを紹介します。
記事のサマリー:製造装置構造、条件パラメータ、消耗部材の組み合わせなど、最適な製造条件(プロセス条件)をインフォマティクス技術を駆使して高速に見つけ出し、開発期間を圧倒的に短縮する技術が「プロセスインフォマティクス (PI)」
プロセスインフォマティクス概論
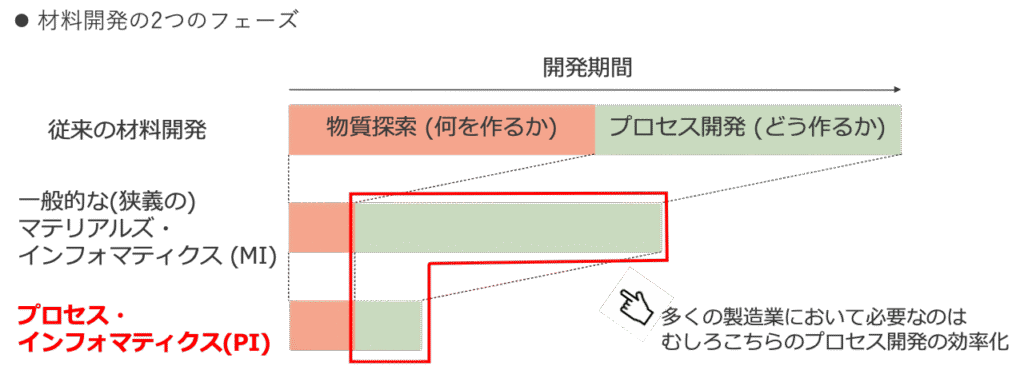
プロセスインフォマティクスとは何か
製造業の開発・製造におけるインフォマティクス応用が盛んに行われています。マテリアルズインフォマティクス(MI)による新材料の発見や、自動設計ツールによる最適な製品設計など、AIを活用することで従来ではとてもたどりつけなかった性能をもつ材料・製品設計を見つけることが可能であり多くの成果が出ています。しかし、これらは「何を作るか」を最適化する技術であり、製品を「どう作るか」については考えられていない場合が多いです。
プロセスインフォマティクス(PI)は、製造工程(プロセス)を最適化、つまり「どう作るか」を最適化する技術です。製造装置構造、条件パラメータ、消耗部材の組み合わせなど、最適な製造条件をインフォマティクス技術を駆使して高速に見つけ出し、開発期間を圧倒的に短縮する技術が「プロセスインフォマティクス (PI)」です。
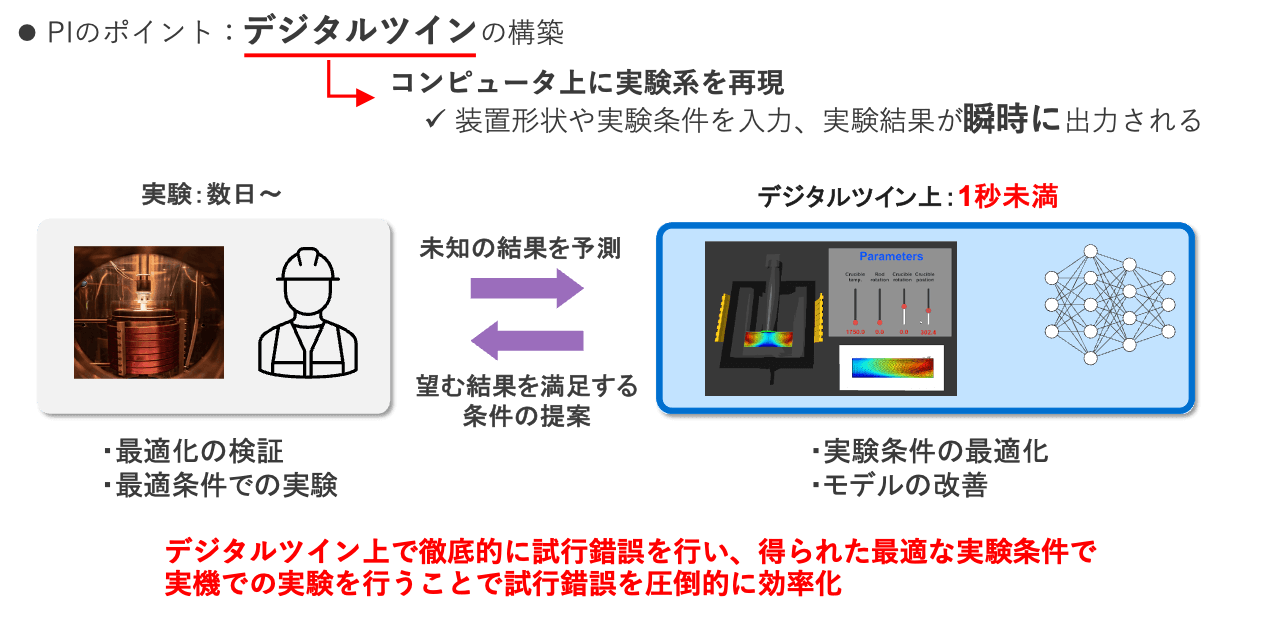
デジタルツインの構築と仮想実験
プロセスインフォマティクスの鍵となるのが、製造プロセスのデジタルツイン構築です。デジタルツインとは、シミュレーションや機械学習を用いて製造装置をコンピュータ上に再現することで、実験条件や装置形状を入力すると実験結果の予測ができる技術です。機械学習を用いることでこのような予測(仮想実験)を高速化することができ、ものの一瞬(1秒未満!)で、ある条件に対する実験結果を実際に実験を行わなくても予測することができます。
この高速予測を用いて「ここの回転数変えたらどうなるんだろう?」「消費電力抑えなきゃいけないからここの温度下げたいんだけど大丈夫なんだっけ?」といった確認を素早く行なったり、「加工レートと平坦性が最大となるような加工条件」「成膜速度が最大となるが表面品質も高い成膜条件」といった理想的なプロセス条件をあらゆる実験条件、装置形状を仮想空間上で網羅的に探索することで発見したりできます。見つかった最適な条件で実際の装置で試作することで製品開発の期間とコストを大幅に短縮することが可能となります。
DXの先にPIあり
DX白書2023によると、DXに取り組んでいる日本企業は2021年で55.8%、2022年では69.3%にまで達しており、DXの取り組みは当たり前になりつつあります。2022年の段階で「DXの成果が出ている」と回答した日本企業も58%にまで達しており、DXで成果を出した企業も増えてきています(米国では89%であり、大きく遅れをとっていることは事実です)。
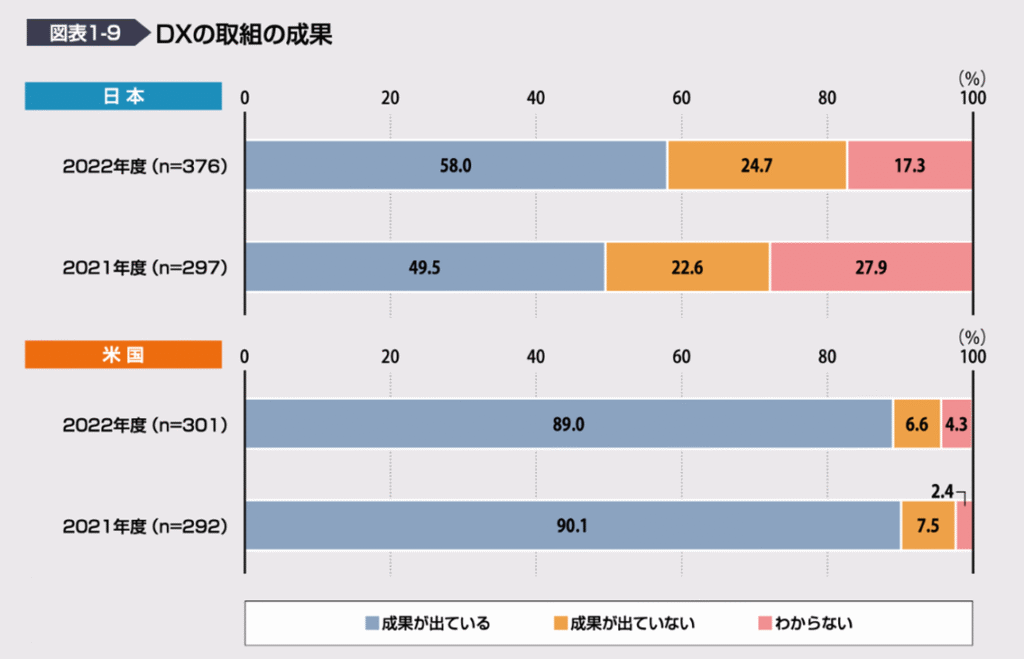
しかし、「DX」という言葉が単なる「デジタル化」という意味で認識されていることも多く、X=トランスフォーメーションについてまで意識が向けられていることはあまり多くありません。デジタル化により組織文化から変革し、価値を創出することがDXであり、その意味ではプロセスインフォマティクスはDXにおけるXのための強力な手法と言えます。ただ、どうしてもDXという言葉に単なるデジタル化という印象を抱いてしまう方が多い現状、「DXの先はPIだ!」として、DXによりデジタル化された知見・データを用いてPIによって生産効率、歩留や製品性能の向上に繋げていくというストーリーがPIや本当の意味でのDXを進めていくポイントなのではないかと思います。
プロセスインフォマティクスの基礎技術
デジタルツインを用いた実験条件の高速・大量予測と数理最適化アルゴリズムを組み合わせて、実験条件や装置形状の最適化(プロセス最適化)を圧倒的に効率化できます。本章では、プロセス最適化の鍵となる機械学習モデルの構築と最適化技術について説明します。初歩的な説明なので、機械学習や数理最適化について勉強したことのある方は本章を読み飛ばしても大丈夫です。
機械学習のざっくり解説
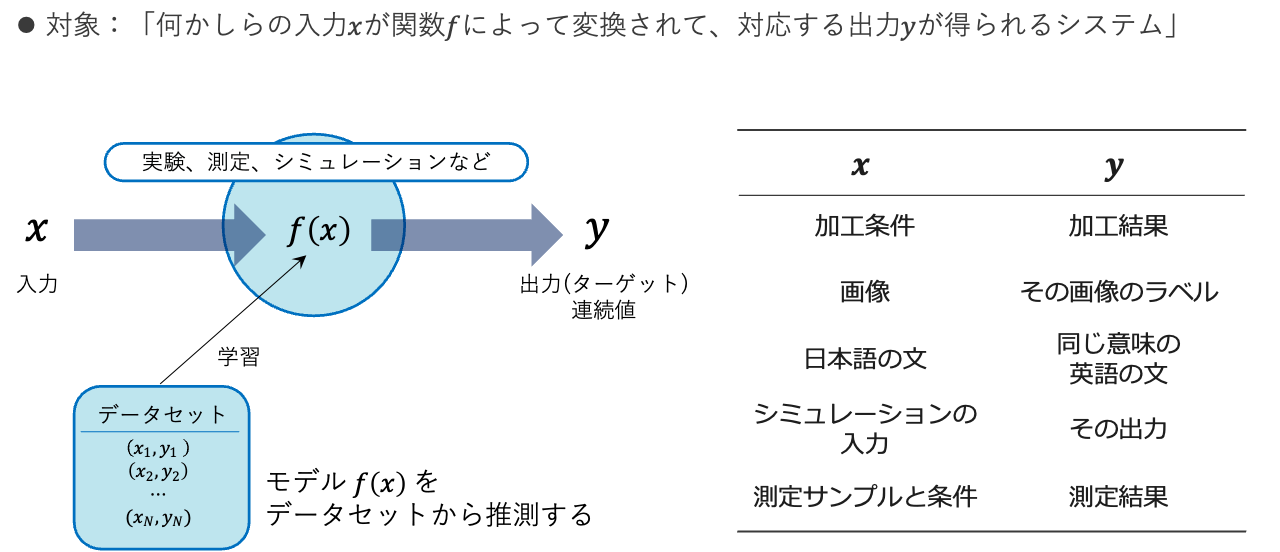
機械学習とはデータに潜むパターンや意味を抽出(「学習」)する技術の総称です。まず、何かしらの入力 \(x\) に対して、対応する出力 \(y\) が得られるシステムを考えます。例えば、加工条件 \(x\) に対して、実際に加工した結果が \(y\) であったり、画像 \(x\) に対してその画像のラベル(それが何の画像か)が \(y\) であったり、翻訳システムでいうと日本語の文が \(x\) で同じ意味の英語の文が \(y\) となります。データセットとしてこの \((x, y)\) の組を用意し、その関係性を近似するつまり、 \(y = f(x)\) となるモデル \(f(x)\) を構築するのが機械学習です。このようなモデルに与える \((x, y)\) の組を教師データといい、このような学習の仕組みを教師あり学習といいます。
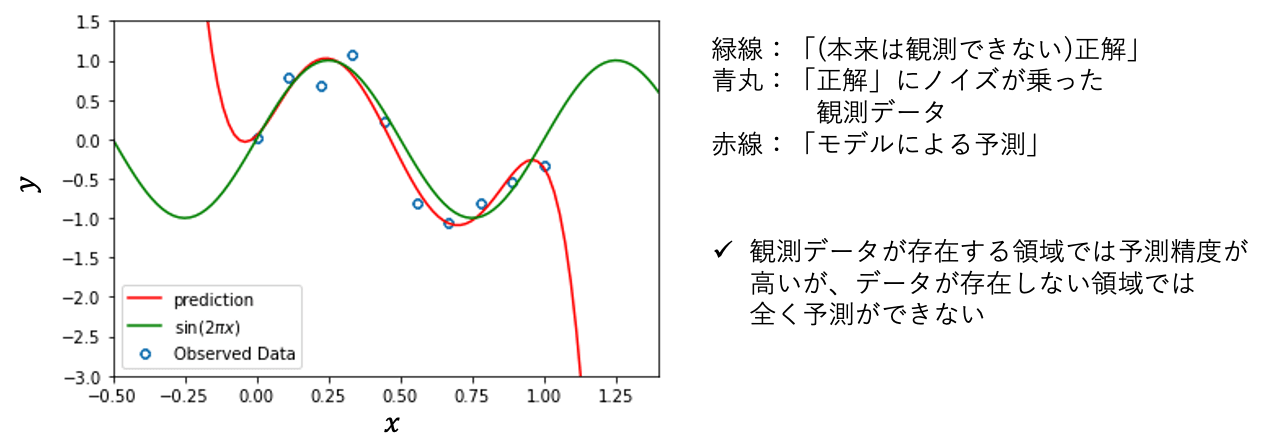
下の図は \(x\) と \(y\) の関係を学習し、\(y = f(x)\) となるモデル \(f(x)\) を作成するイメージ図です。
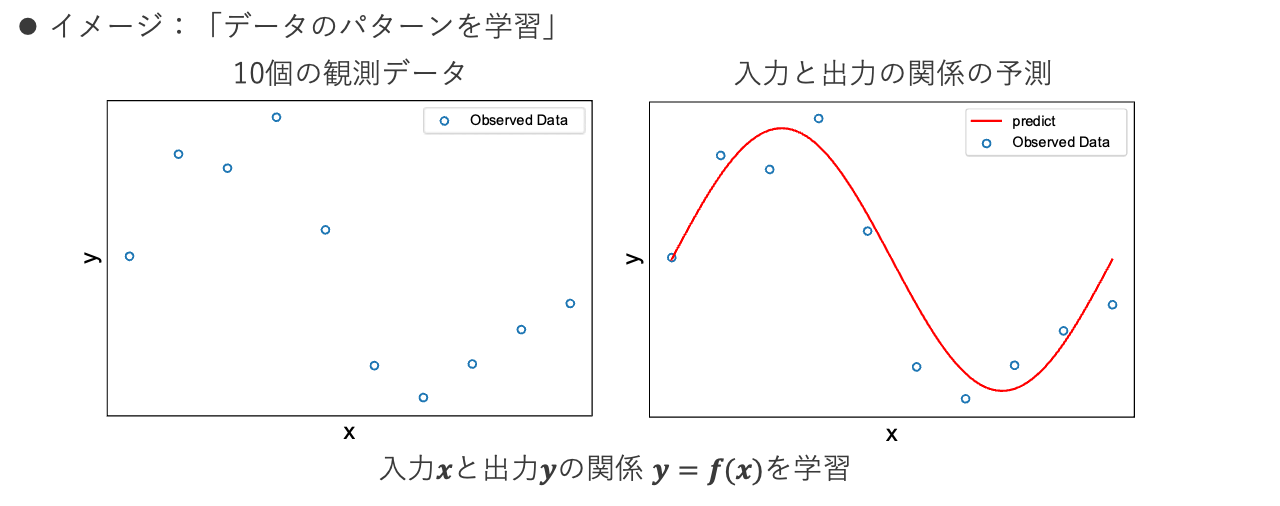
左の図に10個の観測データが青点でプロットされており、この\(x\) と \(y\) の関係をうまく表す右の図の赤線のような関数をデータのみから作ることが教師あり学習の目標です。この例では入力変数も出力変数も1次元なのでグラフを書いて視覚的に見ることができるので「機械学習なんて小難しい技術使わなくてもそんなことはできるじゃないか!」と思われるかもしれませんが、このようなことを入力変数や出力変数の種類が多くなってもできるというのが機械学習の強みです。重回帰分析、多変量解析の経験がある方にはイメージしやすいと思います。関数近似を非線形・高次元に拡張し、非常に柔軟なモデリングができることが機械学習の強みと認識していただいて構いません。
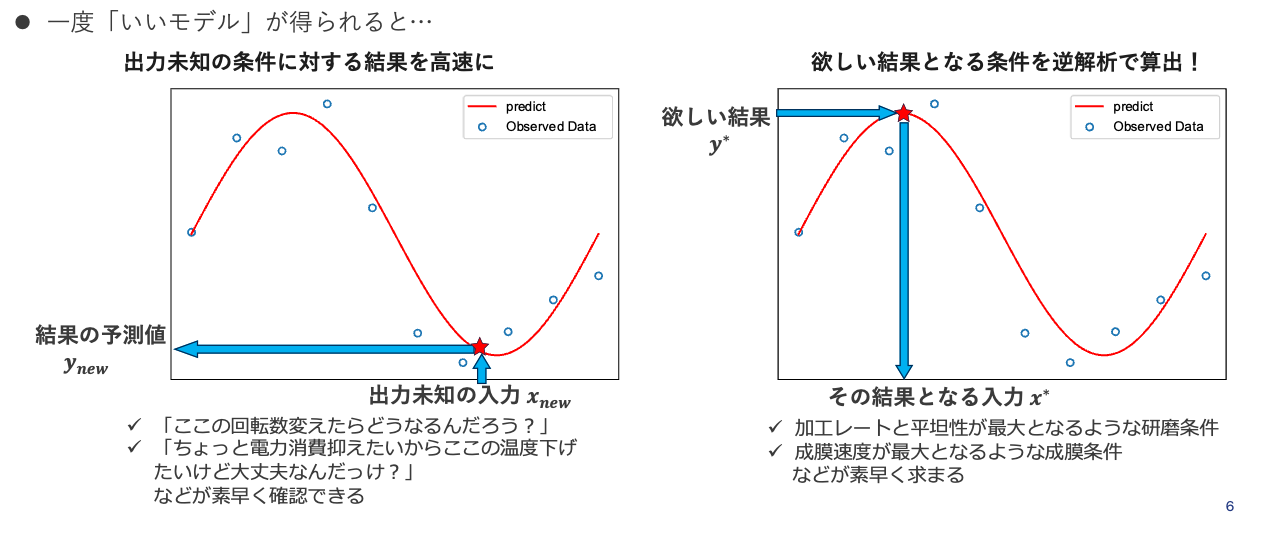
一度精度の高いモデルを構築できれば、出力がわからない新たな \(x\) に対して対応する出力 \(y\) を求めることが可能になります。例えば、実験したことのない実験条件 \(x^*\) での結果 \(y^*\) の予測が可能になるということです。また、機械学習モデルによる予測は一般に非常に高速(予測に1秒かかるモデルは結構遅いという感覚)なので、お金も時間もかかる実機での実験の結果を低コストで高速に予測できるということです。また、次節で解説する数理最適化アルゴリズムと組み合わせることで、欲しい結果となる実験条件を逆解析的に求めることも可能となります。これにより、開発にかかる時間とコストを大幅に削減することが可能となります。
下の図は未知の \(x\) に対する \(y\) の予測(左図)と欲しい結果 \(y^*\) となる実験条件 \(x^*\) の逆解析による算出のイメージ図です。
数理最適化のざっくり解説
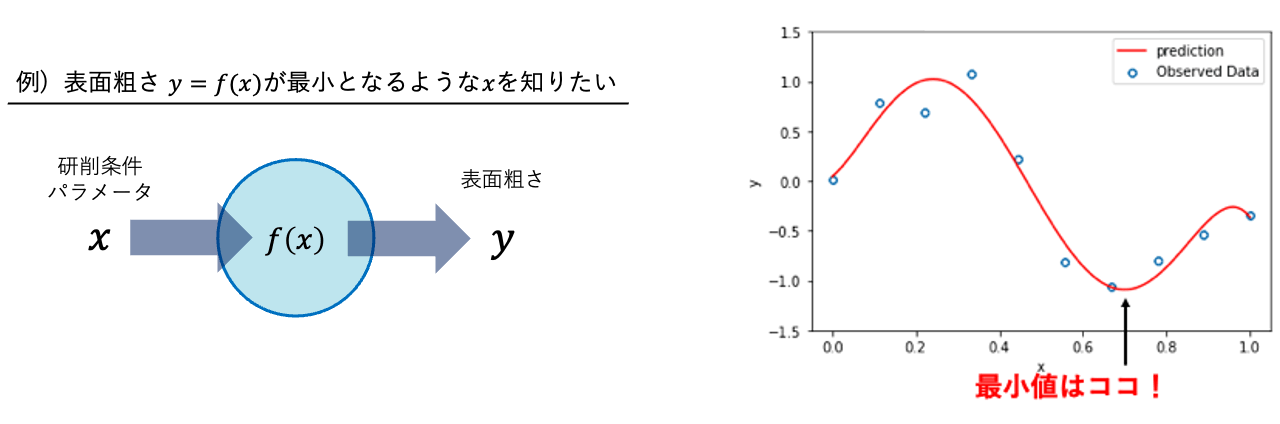
数理最適化とは、「ある関数 \(f(x)\) が最小となるような \(x\)」を求める技術です。最適化したいパラメータである \(x\) を設計変数、最適化の指標である \(f(x)\) を目的関数といいます。例えば、「加工条件を設計変数 \(x\) とし、その条件で加工した結果の表面荒さ \(f(x)\) が最小となるようにしたい」といった例が考えられます。
目的関数の設計を工夫することで様々な「欲しい結果」となる条件を見つけることができます。例えば、「製品の熱伝導率が、ある値 \(y^*\) となるようなプロセス条件 \(x\) を見つけたい」という問題に対しては目的関数をその値との差 \(|y^* – y|\) として最適化問題を解けば \(y^*\) に近い出力となる条件を求めることができます。
目的関数 \(f(x)\) が最小値となる \(x\) を求める数理最適化には様々なアルゴリズムがありますが、その多くは「ある \(x\) に対する \(f(x)\) の値の評価」を繰り返し行う必要があるため、与えられた \(x\) に対する \(f(x)\) の値を求めるコストが高いと適用は難しくなります。そこで、ある条件に対する結果を瞬時に計算可能である前章のデジタルツインが活躍するということです。
プロセスインフォマティクスでできること
本章はプロセスインフォマティクスで何ができるか、「シミュレーションが使える場合」「開発用の装置などパラメータ振りができる場合」「量産用の装置などパラメータがある程度固定されている場合」の3つの場合について紹介していきます。
シミュレーションベースのデジタルツインによる最適化
まずは「シミュレーションが使える場合」について、サロゲートモデルを用いた最適化について紹介します。サロゲートとは代理という意味であり、シミュレーションの入力\(x\) と計算結果\(y\) を教師データとして与えることで未知の計算条件に対してその計算結果の予測を行える機械学習モデルを「シミュレーションを代理できるモデル」という意味でサロゲートモデルと呼びます。一度サロゲートモデルを構築してしまえば機械学習による予測は高速に行えるため、繰り返し計算が必要な最適化アルゴリズムを適用できるようになります。サロゲートモデルを用いた最適化の手順は以下のような流れです。
- 実機をよく再現するシミュレーションを構築し、教師データとして入出力の組\((x, y)\) を得る
- それらを教師データにした機械学習モデル(サロゲートモデル)を構築する
- 「理想的な状態」になるような装置形状やプロセス条件を最適化によって求める
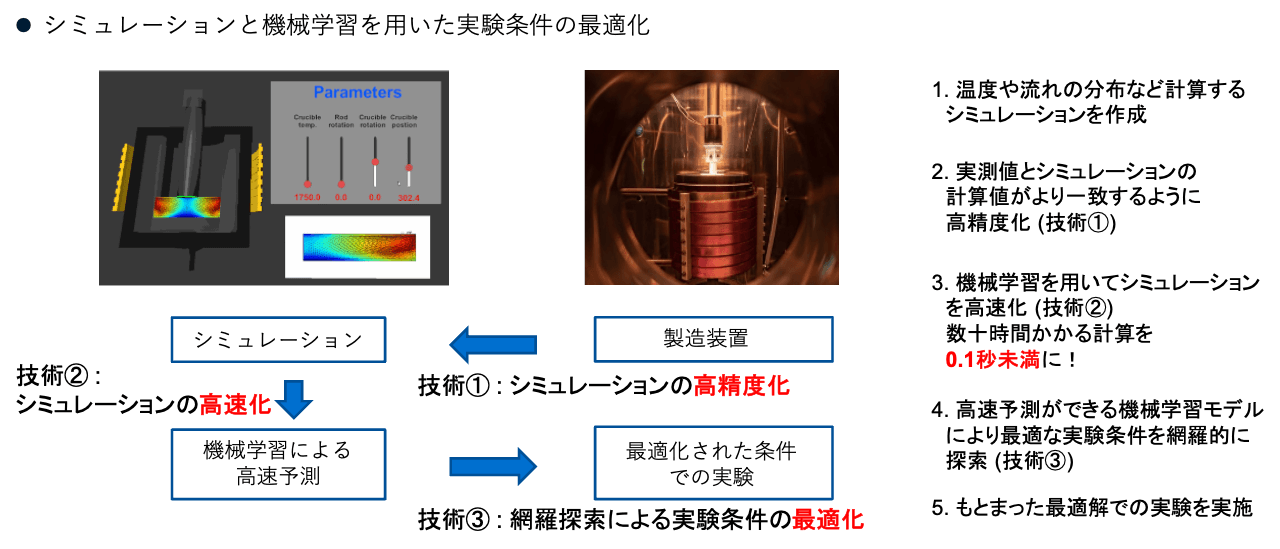
重要なのは実測値と合うようなシミュレーションの構築と「理想的な状態」の定義、つまり目的関数の設計です。実測値とよく合うシミュレーションを構築するには装置の適切なセンシングや物理現象の理解など、装置やプロセスについての十分な知見が必要となります。また、最適化によってどのような状態にしたいか、つまり目的関数を適切に設定するにはプロセスの十分な理解が必要です。例えば、サロゲートモデルによって装置内の温度や流れ、応力分布などが求まったとして、「どのような温度や流れ、応力分布にしたいか」を設定するのはプロセスエンジニアの重要な仕事となります。「ここの温度をこうして、この部分の流れが不安定にならないようにしたい」といったアイデアを最大化する装置形状やプロセス条件を求められることがこの手法の強みと言えます。
実験ベースのデジタルツインを用いた適応的実験計画
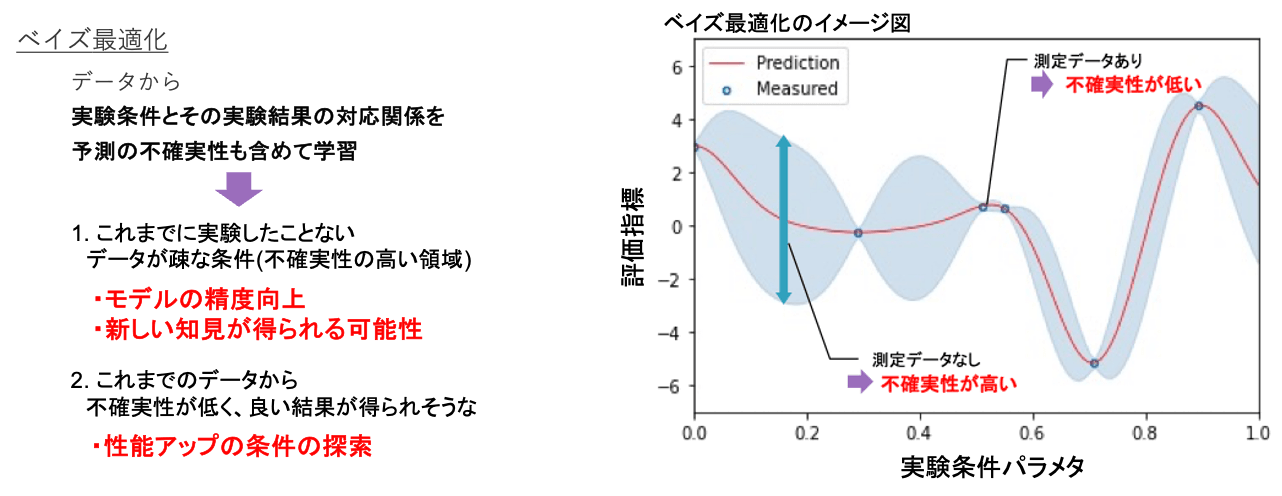
開発用の装置が用意できる場合など、「パラメータを振った実験が可能な場合」、ベイズ最適化による適応的実験計画が有効です。ベイズ最適化では入出力の組\((x, y)\) からモデルを構築する際、予測の不確実性まで含めて予測できる確率的手法(ガウス過程回帰など)を用います。通常の回帰モデルのようにある\(x\) に対して1つの\(y\) を予測値として出力するのではなく、\(y\) の確率分布を返します。つまり、「この\(x\) に対してはこの\(y\) である確率がいくつ」という値を出力します。右下の図は確率分布として予測するイメージであり、「ある\(x\) に対する\(y\) の値が薄い青の帯の範囲に収まる確率が〇〇%」という予測が得られるわけです。データがたくさんある領域では不確実性が低い、つまり薄い青の帯が狭くなっており、データが疎な領域では不確実性が高い、つまり帯は広くなっていることが分かります。ここから、次に実験する(=データを取得する)条件の選び方として…
- これまでに実験したことのないデータが疎な条件を選択する、つまり「不確実性の高い領域」
- これまでのデータから不確実性が低く、「いい条件が得られそうな領域」
上記の2つの方針が得られます。1の不確実性の高い領域での実験では、モデルの精度向上や今までにない新しい知見が得られる可能性があります。2の方針では性能アップの条件が得られることが期待できます。性能アップの期待値や不確実性の大きさなど、次の実験条件を決定するために計算する指標を獲得関数と呼びます。獲得関数に基づいて実験を行い、得られたデータを用いて再度モデルを学習し、新しいモデルを用いて再び次の条件候補を算出していきます。
シミュレーションベースの手法と比較して、実験データを直接学習するのでシミュレーション構築が難しい、支配方程式が未知な複雑な現象 にも適用可能というメリットがあります。ベイズ最適化の手順は以下の通りです。
- 設計変数と目的関数(最適化したい量)を設定する。
- 初期実験を行い、最初の確率的な予測モデルを作成する。(実験計画法を用いることが多い)
- 得られたモデルから獲得関数を計算し、次の実験条件の候補を得る。
- 実験条件の候補の中から選択し、次の実験を行いデータを取得する。
- 新しいデータを用いてモデルを更新。2に戻る。
ベイズ最適化は、「十分な知見により最適化したい変数が完全に決まっている」または「なんらかの事情により最適化できる変数が定まっている」状況で、「あとはパラメータ最適化だ!」というときに使える手法です。
製造(量産)時のデータを用いたプロセス異常検知
量産時のデータなど、パラメータがある程度固定されている場合、センサーデータを活用したプロセス異常検知が有効です。製造業における生産データは正常データに比べて異常データ(不良データ)が非常に少ないという特徴があります。この特徴を利用して、大量の正常データでセンサ ー間の相関を学習し、その相関と崩れた場合を異常とみなす方法が用いられます。また、どのセンサー間の相関が正常時と異なるかを確認することで、異常の原因の特定に役立てることも可能です。簡単な例としてはヒータの出力上昇に対してある温度センサーの値の上昇の応答が正常時に比べて悪いというときに、ヒータの故障や断熱や冷却関連の不具合があるといったあたりをつけることが可能となります。
プロセスインフォマティクスの導入事例
本章ではプロセスの導入事例を3つ紹介していきます。ちなみに本テックブログでは今後、様々なプロセスに対するプロセスインフォマティクスの導入事例記事を公開していく予定なので、そちらもご期待ください。
半導体結晶成長プロセスの最適化 (シミュレーションベース)
まずはシミュレーションベースのデジタルツインを用いた最適化の例として、半導体SiCの結晶成長プロセスの最適化の事例をご紹介します(参考文献[2]~[4])。SiCは自動車、鉄道、発電所など大電流、高耐圧が求められる領域で電力の変換を高い効率で行えるパワー半導体として優れた物性を持ち、省エネに貢献しています。
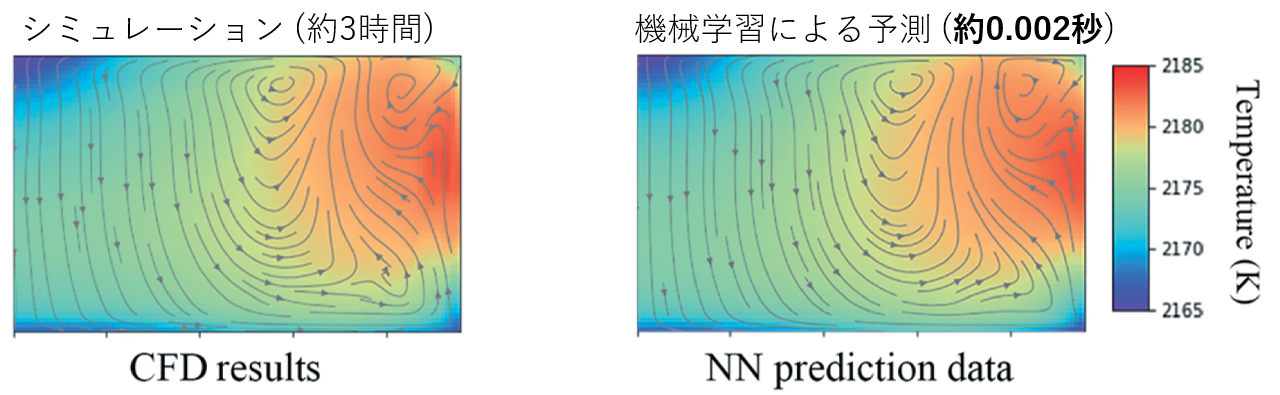
実験には多くのお金と時間が必要なので開発の効率化には結晶成長炉内部の熱流体シミュレーションなどのCAE活用が有効です。さらにシミュレーション結果を教師データとして学習し、シミュレーションの入力\(x\) に対しその計算結果\(y\) を予測する機械学習モデルを構築することで計算結果を一瞬で予測することができるようになります[2]。このようにシミュレーションの入出力を学習した機械学習モデルをサロゲートモデル(代理モデル)といいます。 下の図は文献[3]のFig. 3より炉内の温度・流れ分布のシミュレーションによる予測(左図)とサロゲートモデルによる予測(右図)で、シミュレーション結果を高精度に予測できていることがわかります。また、シミュレーションでは約3時間かかる計算を機械学習ではわずか0.002秒で予測可能です。
サロゲートモデルによる計算の高速化ができると、数理最適化アルゴリズムによって欲しい結果となるような実験条件や装置形状を求めることが可能になります。下の図は最適化前後の結晶や坩堝形状を比較したものです[4]。最適化の目的関数は、1) 結晶の大型化、2) 坩堝底の雑晶の抑制、3) 坩堝壁面の変形の抑制の3つで、大きな結晶を坩堝底への余計な結晶(雑晶)の析出を防ぎつつ、坩堝が割れると危険なので変形を防ぎながら作製したいという設計思想です。
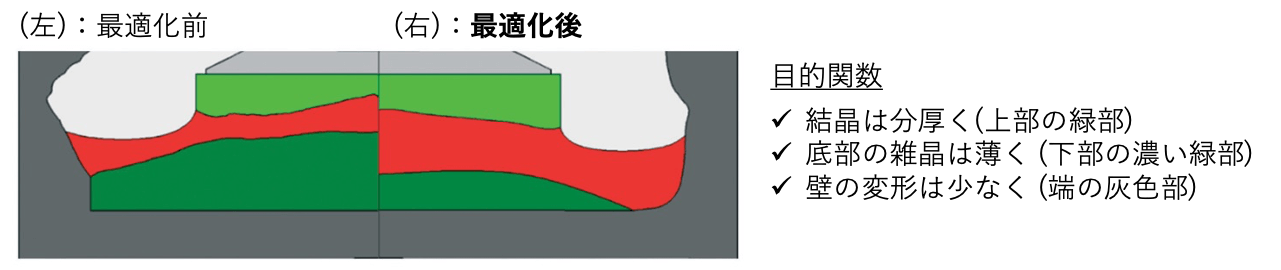
上図の右半分が最適化後の坩堝の状態であり、最適化前の左半分に比べて、結晶(上部の緑部)は分厚く、坩堝底の雑晶(深緑部)は薄く、壁の変形(端の灰色部)は少なくなっていることがわかります。このように理想的な状態を達成するための実験条件や装置形状を求めることができるのがシミュレーションベースの最適化の強みです。
半導体の薄膜成長プロセスの最適化 (実験ベース)
次に実験ベースのデジタルツインによる最適化の例として、Siの薄膜成長プロセスの最適化の事例をご紹介します5。Siの薄膜成長(エピタキシャル成長)とはSi基板上にさらに薄膜のSiを成長させるプロセスで、基板とは異なる特性を持つ層を追加することでデバイス特性の制御が可能となります。
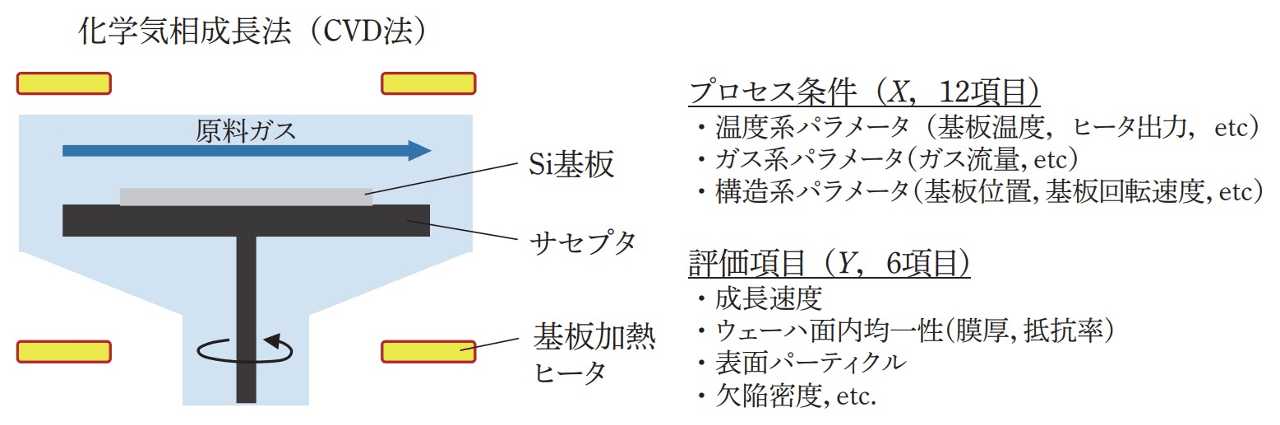
Siエピタキシャル成長は高温に加熱したSi基板上に原料ガスとキャリアガスを流し込み、基板表面にSiを成長させる手法であり、基板の加熱条件や基板位置、回転数、各種ガス流量など非常に多くのプロセスパラメータがあります。文献[6]より、装置の模式図を以下に示します。目標としては膜厚の均質性やパーティクルの付着は防ぐなどの品質制約を満たしつつ成膜速度を最大化することです。このような化学反応が絡む複雑な界面現象は支配方程式に基づいた計算は難しく、ベイズ最適化などの実験ベースのモデリング・最適化 (本記事3.2)が有効となります。
この事例では、複数の制約のもとでの成長速度の改善の期待値に基づいた制約付きベイズ最適化を行い、一度に複数の条件候補を提案して最適化を進めるバッチベイズ最適化が用いられています。また、品質項目によっては測定・評価に時間がかかるものがあり、最適化ループを律速してしまうため、ある品質項目のみ制約に用いる単制約ベイズ最適化と全ての品質項目を制約とする多制約ベイズ最適化を組み合わせて適応的に制約を加えることで最適化効率を向上させています。
さらに、ベイズ最適化による探索ではこれまでに検討したことのないプロセス条件も提案されるため、一部条件では装置エラーが発生してしまいますが、プロセスエンジニアの知見に基づいて装置エラーに関連する項目を抽出し、それを機械学習によって予測して制約をつけることで装置エラーの回避に成功しています。
このベイズ最適化により、5つの品質項目を満たしながら成膜速度を約2倍にまで上昇させることに成功しました。追加の設備投資なしでパラメータチューニングのみで生産効率の向上を達成できたということになります。このようにパラメータの選択や装置エラーに関する制約条件など、プロセスエンジニアの知見の活用が非常に重要となります
成膜条件の自律探索 (ロボットによる自動実験)
最後の例として、ベイズ最適化による実験条件提案とロボットによる自動実験を組み合わせて自律的に条件探索をする事例をご紹介します。一杉らによる自律的な物質探索ロボットシステムでは、ベイズ最適化によって求まった実験条件候補を自動搬送アームを用いて自動で試料投入〜成膜〜評価まで行い、そのデータでモデルを更新し、次の条件候補を提案し、それを自動で実験するループを構築することで、全自動かつ自律的(closed loop)な合成条件の最適化システムを構築しました[7]。その結果、人間が介在することなく二酸化チタン薄膜の電気抵抗最小化に成功しました。当該プレスリリースから自動実験装置とベイズ最適化との組み合わせの模式図を示します。

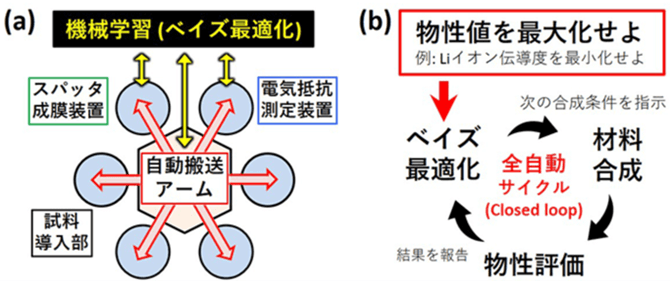
人間の介在がないため、連続で様々な条件で合成し続けることが可能であり、マテリアルズインフォマティクスのような物質探索と組み合わせて革新的な材料合成につながることが期待できます。
こちらの例は前の例の専門家による適応的な判断が入るHuman-in-the-loopな手法とは対極にある、一切人間が介在しない手法であり、どちらが適切か自身のプロセスの課題をしっかりと考えた上で選択することが重要と言えます。
プロセスインフォマティクス成功の鍵
ここまでプロセスインフォマティクスでできること、その事例について紹介してきました。プロセスインフォマティクスを成功させるために最も重要なのは、「製造プロセスの知見に基づく適切な課題設定」と「課題を解くのに十分に情報を持ったデータの収集」です。本章ではこれら2点に注意しながら、プロセスインフォマティクスの進め方について解説していきます。
製造プロセス領域の知識も含めた総合的なインフォマティクス
機械学習を用いたプロジェクトは基本的には以下の手順で進められます。
- 問題の定義 (目標の設定)
- 評価指標の定義
- データの準備
- 手法の選択
- モデルの訓練と評価
- モデルの活用 (モデルの実機への実装や条件最適化など)
ここで最も重要なのは1.の問題の定義です。試作品の性能を予測したいのか、異常を自動で検出したいのか、性能や歩留を向上させる条件を探索したいのかなど、解決したい課題は何かを明確に定め、その課題に対して機械学習が有効な手法であれば機械学習を用います。もし、機械学習を使わなくても解決できるのであれば、無理に機械学習を使おうとすることはNGです。機械学習はあくまで統計的な予測なので、100%はありえません。「機械学習が使えそう」のポイントとしては、以下の通りです。
- 「人間がやってもなんとなくできそうなこと」を「人間より素早く・正確に・大量に」
- 低次元なら可視化ができて人間でもなんとかなるけど、高次元になると難しい
- 予測結果に一定の間違いが含まれることを許容できる (絶対に外さないモデルは不可能)
そして、明確な課題が設定でき、手法として機械学習が適切であるとなれば、次は評価指標の定義です。機械学習モデルを作成し、「正解率95%」のモデルができた場合、これは「いいモデル」と言えるでしょうか?例えば、不良率5%の装置に対して異常検知を行う場合「どんなデータを入力しても正常と返す」モデルの正解率は95%となります。つまり、このような問題においては正解率95%のモデルは全く使えないモデルということになります。
「装置内のある場所の温度を±1℃の誤差で推定できるモデル」も、その1℃が目標とする現象を制御するのに十分な精度かどうかで「使えるモデル」かどうかは変わってきます。
至って当然のことを言っているだけですが、特にデータ解析プロジェクトにおいて、モデル構築と改善のループが回っている際、精度向上に捉われてしまい本来の目標を見失ってしまうことが非常に多く見られるため、ここで強く意識しておく必要があります。
問題の適切な設定、評価指標の定義、解析結果の吟味には製造プロセスや装置に対する深い理解が重要となります。「データサイエンスの分かる製造業エンジニア」または「製造プロセスの分かるデータサイエンティスト」のどちらかが必ず必要になるのが製造業におけるインフォマティクス応用のポイントです。次はデータ取得の際の注意点について見ていきます。
課題を解くのに十分な情報を持つデータの収集
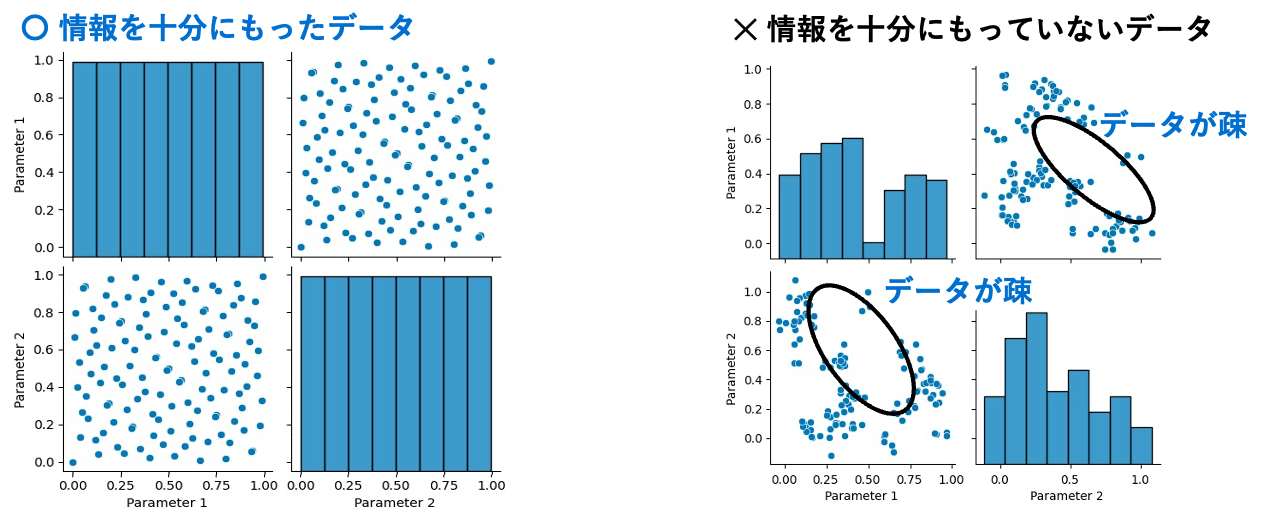
プロセスインフォマティクスに必要なデータはただ量の多い”ビッグデータ”ではありません。課題解決のために十分な情報を持ったデータが必要となります。機械学習モデルはあくまで学習に使ったデータのパターンを数式で近似しているだけなので、学習に使ったデータが存在しない領域における予測精度は低くなってしまいます。下図にそのイメージを示します。
例えば、量産データに対する異常検知がしたい場合は、大量の良品データを集める必要がありますが、その際には不良の状態を十分に検出できるだけのサンプリングレートでセンサーデータを取得する必要があります。
また、条件最適化がしたいときは、十分な変動を持つデータを取得する必要があります。右下の図のようにデータが疎な領域があるとその付近での予測精度はどうしても悪くなってしまうため、探索したい領域で十分な変動を持ったデータを取得する必要があります。
プロセスインフォマティクスに取り組むプレイヤー
プロセスインフォマティクスに取り組むメーカーはここ数年で飛躍的に増加しています。例えば半導体装置メーカーの東京エレクトロンではプラズマ成膜のプロセス最適化に機械学習を活用し、短時間で高品質な薄膜形成を実現しています[8]。半導体材料メーカーのグローバルウェーハズ・ジャパンではシリコン薄膜形成のプロセス最適化[5]や製品材料の特性を製造中にリアルタイムで予測するシステムを構築しており[9]、プロセスインフォマティクスの導入が進んでいます。これら以外にも非公開のものも含めて非常にたくさんの事例があり、プロセスインフォマティクスの盛り上がりが感じられます。
一方で、プロセスインフォマティクスが対象とする製造データは極秘であることや、再現性が取りづらい(工場や実験室で同じ装置を隣に並べて同じ条件で実験をしても結果が異なるということもザラにある)ため、マテリアルズインフォマティクスのようなデータベース構築などの一般化の難易度は非常に高いです。このようなデータの秘匿性や個別性により自社以外のプロセスやデータに対する知見が貯まりにくい性質があります。そのため、様々なプロセスやデータを解析し、各社の秘匿性を保ったまま一般化できる部分を抽出することでプロセスインフォマティクスを体系化し、導入が楽になる知見を貯めていくには第三者的プラットフォーマーが必要となります。
マテリアル・プロセスイノベーションプラットフォーム (産総研)
産業技術総合研究所(産総研)は2022年4月にプロセスインフォマティクスによる材料開発を進める拠点としてマテリアル・プロセスイノベーションプラットフォーム(MPIプラットフォーム)を設立しました[10]。MPIプラットフォームは以下の3拠点からなります。
- 触媒の自動合成および評価を行う先進触媒拠点(つくばセンター;つくば市)
- セラミックス・金属材料について粉体合成、成形、焼成から物性評価まで一気通貫で行える装置群を1箇所に集め、物性情報と紐付けてPI活用を促進するセラミックス・合金拠点(中部センター ; 名古屋市)
- 有機材料を中心に各種原料の調整から混合・成形加工まで一気通貫で行い部素材の構造と製品特性を紐づけるための分析・評価装置群を備える有機・バイオ材料拠点(中国センター;東広島市)
各拠点の装置群では一部の装置では自動的に入出力データの取得が行われ、サーバに集約するシステムも導入されており、PIモデル構築に活用されます。
MPIプラットフォームは、以下の2つの目標達成に向けて、整備・運営が行われています。
- 拠点利用による社会実装支援
- データ駆動型研究開発基盤の整備
アイクリスタル株式会社
アイクリスタル株式会社は2019年11月に創業の名古屋大学発のスタートアップ企業です。手前味噌ですがプロセスインフォマティクス専業の企業しては先駆け的存在と言っても過言ではないでしょう。次世代半導体SiCの結晶成長プロセスをAIを用いて最適化する研究(文献[2]~[4]など)をルーツとし、創業以来、数多くのメーカーのプロセス最適化を行なっています。受託解析をメインとし、人材育成からPI導入や活用のコンサルティング、OJTといった内製化支援までプロセスインフォマティクスのソリューションを総合的に展開しています。研究開発にも力を入れており、NEDOプロジェクトや企業・大学との共同研究も積極的に行なっています[11],[12],[13]。
半導体分野を事業ドメインの中心に置きながら、セラミクスやガラスの製造、金属加工などさまざまな業種に対し、データ駆動の製造業を実現し、モノづくりのやり方を革新すべく邁進しています。
あらゆる製造業に適用可能なプロセスインフォマティクス
製造プロセス開発の新しい方法論「プロセス・インフォマティクス」をご紹介しました。 ここ数年で著者の所属するアイクリスタルへのご相談も「何からやれば…?」から「考えてみたがこれでいいか?」「やってみたがうまくいかない」といったものへと変化してきています。
インフォマティクス自体は課題解決の手段であり真の競争力はものづくりにあります。プロセスインフォマティクスにおいて、データの質やものづくりの知見が最重要です。機械学習の分野ではGarbage in, Garbage outという有名な言葉があり、要は品質の悪いデータからは品質の悪いアウトプットしか得られないということです。この意味で日本はプロセスインフォマティクスに非常に適していると感じます。
新しい開発体制やデータの取得・蓄積や成形など、地道な取り組みになりますが、日本のモノづくり企業が勝ち続けるためには必須の技術といえます。外部連携をうまく活用して素早く取り組み、着実に成果をあげることがモノづくりを革新する上で重要となります。プロセスインフォマティクスを適切に活用して製造業をより一層盛り上げていきましょう!
アイクリスタルはプロセスインフォマティクスのプロフェッショナル集団です。当社の技術やソリューションに関心をお持ちの方は、ぜひ当社のホームページで詳細をご確認ください。
製造業におけるPIの最適なパートナーとして、皆様のご期待に応えます。
お問い合わせはこちら:お問い合わせフォーム
お気軽にご連絡ください。
参考文献
- 情報処理推進機構IPA , DX白書2023, https://www.ipa.go.jp/publish/wp-dx/gmcbt8000000botk-att/000108041.pdf ↩︎
- Y.Tsunooka et al., Cryst Eng Comm,(2018), 20, 6546, https://pubs.rsc.org/en/content/articlelanding/2018/ce/c8ce00977e ↩︎
- W. Yu et al., CrystEngComm, (2021), 23, 2695-2702 https://pubs.rsc.org/en/content/articlelanding/2021/ce/d1ce00106j ↩︎
- Y. Dang et al., Cryst. Eng Comm, (2021), 23.9, 1982-1990 , https://pubs.rsc.org/en/content/articlelanding/2021/ce/d0ce01824d ↩︎
- K. Osada et al., Mater. Today Commun, (2020), 25, 101538, https://www.sciencedirect.com/science/article/pii/S2352492820325496 ↩︎
- 沓掛健太朗 応用物理 第89巻 第12号 (2020) 711-714 , https://www.jstage.jst.go.jp/article/oubutsu/89/12/89_711/_pdf ↩︎
- 東工大プレスリリース , https://www.titech.ac.jp/news/pdf/web-tokyotechpr20201119-shimizu-m15g8osq.pdf ↩︎
- 守屋剛 応用物理 第90巻 第5号 (2021) 290-293,
https://www.jstage.jst.go.jp/article/oubutsu/90/5/90_290/_pdf ↩︎ - グローバルウェーハズ・ジャパン プレスリリース,
https://www.sas-globalwafers.co.jp/technical/img/news_20201113.pdf ↩︎ - 産総研MPIプラットフォーム/拠点紹介, https://unit.aist.go.jp/dmc/platform/MPI/bases/ ↩︎
- グローバルウェーハズジャパンHP,
https://www.sas-globalwafers.co.jp/technical/img/collaboration_20221213.pdf ↩︎ - 株式会社オキサイド プレスリリース, https://ssl4.eir-parts.net/doc/6521/tdnet/2090433/00.pdf ↩︎
- 日本ガイシ株式会社 ニュースリリース,https://www.ngk.co.jp/news/2024/20240624_1.pdf ↩︎
