
近年はあらゆる領域でデジタル化が進んでおり、これに伴って生成されるデータが爆発的に増加しています。我々が生身の人間である限り、それらを視覚的にわかりやすく提示することは迅速な意思決定や新たな知見の創出のために不可欠なことです。
本稿では、社会において重要性を増し続けている「データの可視化」について、その基本概念から製造業における活用事例まで本質を重視した解説を試みます。
データ可視化の概論
データ可視化の重要性
現代のビジネスや研究の現場では、多様かつ膨大な情報を迅速かつ齟齬なく把握することが求められており、それがプロジェクトの成否を分ける要因の一つとなっています。可視化の技術は、一見つかみどころのない数値群を直感的なチャートとして表現することで、背後に潜むパターンやトレンドを明らかにしてくれるため、ビジネスや研究の現状把握を強力に助け、更なるデータ利活用のためのインスピレーションを与えてくれます。
可視化の重要性と奥深さは何十年も前から認識されており、その証左として可視化に特化した文献が多数存在します。例えば、Edward Tufteは書籍”The Visual Display of Quantitative Information”1において、視覚的表現が如何にデータの本質を捉える上で有効であるかを説いており、グラフィカルに表現する際の原則やデザイン手法を体系的に解説した名著となっています。また、Stephen Fewの研究”Information Dashboard Design”2では、意思決定支援のための効果的なダッシュボード設計の重要性を強調しています。(いずれもweb上にPDF形式(200頁弱)で無償公開されています)
データ分析技術の進歩により、機械学習によるモデリングや生成AIによる自動解析といった高度な技術がますます活用されていくことは明らかですが、依然として、可視化によるデータの理解なくして、それらの最新技術を有効な形で導入することはできないと考えています。本稿ではその根拠を随所でお伝えしていきます。
データ可視化の本質とは
表面的に見れば、データ可視化とは数値を図形化して美的な装飾を施すことに過ぎないと思われます。例えば、適当な数値情報を無為に抽出したものを、棒グラフや散布図等々を用いて図形化すれば、一見、”可視化”が実行できたように見えるでしょう。しかし、そのような可視化は我々に価値をもたらしません。
可視化の本質に迫るための、ひとつの例を作ってみました。次の図のような、何らかの製品を連続で生産している製造プロセスをイメージしてください。
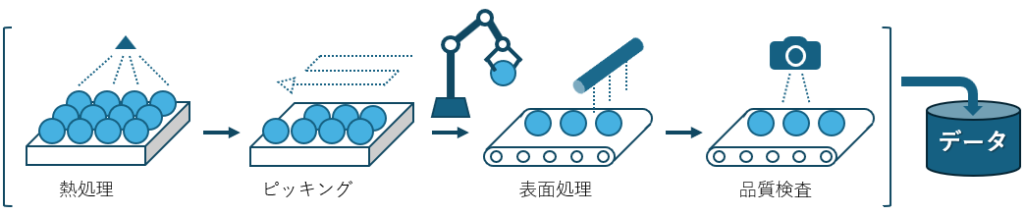
この製造プロセスでは、最後に品質検査工程を設けており、ラインで流れてきた順番に品質値(例えば強度や真球度等々、任意の指標)の計測を行っています。そして、その品質値は時系列でデータベースに格納されています。
ここで、可視化を行ってみましょう。ラインで流れてきた順番(製品番号)を横軸に、品質値を縦軸として折れ線グラフを作成すると次のようになりました。
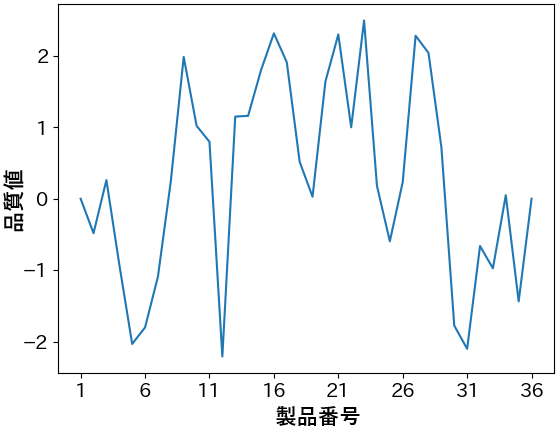
この図からどのようなことが読み取れるでしょうか。品質値は±2.5ほどの範囲でバラついており、目立ったトレンドはないものの、隣り合う製品の品質は割と近い値になりやすいかも、くらいの印象でしょうか。もし、”-2を下回ると出荷できない”というような課題が存在する場合、どこかのタイミングで要因分析に進む必要があるでしょう。
そこで、”この品質データは時系列的に変動していることから、同じく時系列的に制御されている表面処理工程に原因がありそうだ。当該プロセスのIoT時系列データと紐付けて要因分析をしよう…” などという判断を下そうものなら、そのプロジェクトは泥沼化します。なぜなら、データの背後にあるロジックを無視した可視化によって、現状を誤認してしまっているからです。
では、改めて可視化を行いましょう。上記グラフと全く同じ36個分のデータを6個で一行の形に揃え、品質値で色付け(ヒートマップ化)すると次のようになります。折れ線グラフとの対応が把握できるように、ヒートマップの各セルには製品番号を記載しました。
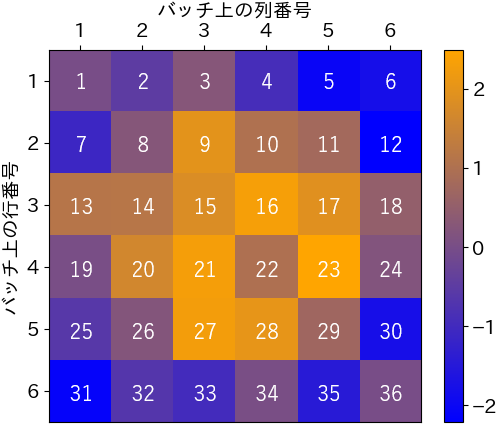
こうすると、明らかに中央から遠ざかるほど品質値が小さい傾向があることが読み取れます。この傾向は、図1の熱処理工程において製品が6×6の並びでバッチ処理されており、そのバッチ上の位置によって加熱条件に差が生じていた(例えば中央に熱源があった)という背景に起因しています。(バッチ処理の制御値・観測値は往々にして個々の製品単位ではなくバッチ単位で記録されるので、データだけでは気付きにくい)
ここで伝えたいのは、折れ線グラフよりヒートマップの方が優れているということではありません。ここから得られる示唆とは、可視化やデータ分析を行う際には、データを生成している系について理解してそれに即した形式や手法を適用しなければ、深い洞察は得られないということです。(弊社が仕事を頂く際に、必ず現地訪問して工程を見学させていただく理由がここにあります)
そして、図3の可視化が我々にもたらした価値とは、”熱源から遠いと品質が下がる”という”気付き”に他なりません。つまり、データ可視化の本質とは、「値の見える化」ではなく、データの背後にある「傾向やロジックの見える化」なのです。
データ可視化における戦略と戦術
上述した通り、効果的な可視化を行うためには多くの考えるべきことがあります。本稿では、必ずしも一般的な表現ではないのですが、データ可視化を ”戦略”と”戦術” に分けて述べていきます。
”可視化”という言葉から想起されやすいのは、棒グラフやヒートマップといった図の形式でしょうか、それともExcelやPowerBIといったBIツールの類でしょうか。それらはいずれも可視化の”手段”であり、本稿ではこれを”戦術”と呼ぶことにします。
対して、可視化には何らかの目的があるので、その為にどのデータをどんな切り口で可視化するのかを考える必要もあります。上述の例のようにデータから未知の傾向を探る場合と、誰かに対してデータを根拠に訴えたい事がある場合では、最適な可視化の”進め方”が異なることが想像できるかと思います。本稿ではこれを”戦略”と呼ぶことにします。
データ可視化の戦略
本章では、どのように可視化を進めるべきかという戦略について解説します。本稿はプロセスインフォマティクスをテーマとしているので、膨大なIoTデータなどから知見を得ることを目的とした、データマイニング的な観点を前提として話を進めましょう。
探索的データ分析(EDA)について
分析したいデータの規模が大きい場合、専門家でない限りはどこから手を付けてよいか分からなくなってしまうのではないでしょうか。そのような場合に有効な戦略としてEDA(Exploratory Data Analysis)と呼ばれる方法論があります。EDAは、データセットの全体像を把握するところから仮説を立てるに至るまで、データから洞察を引き出すための柔軟なアプローチとしてデータサイエンスの分野で広く認知されています。これはフレームワークと呼べるほど分析工程を厳密に定義するものではなく、データセットや分析者によって大きな自由度があるため、本稿では概念的な部分のみ解説します。
EDAの2つの役割
話を簡単にするために、EDAの役割を2つに大別してみました。前提として、分析対象データの背後にあるプロセスや系についてなるべく理解しておき、分析を行う目的について意識しながら進めることが、より効果的なEDAの実施に欠かせないことは留意しておいてください。
役割1:データの全体像を把握すること
分析の流れとして、浅く広くから深く狭くへと進んでいくことがセオリーとなります。テーブルデータを前提とした場合、まずは基礎的な統計量の確認や分布の可視化を行うことによりデータの概要を把握しておくことが欠かせません。
このとき、例えば変数の平均値と中央値に大きな差がある場合やヒストグラムの形状が不自然な場合に、外れ値や異常値を発見することができます。データの欠陥を見つけて取り除くことはその後の分析の精度を高めるために不可欠な要素であるのは勿論のこと、どの期間やどの条件で多く発生しているのかといった気付きを得ることで、データ取得側の改善にも示唆を与えることが出来る重要なプロセスです。
数十次元程度のデータであれば、変数同士の関係性も眺めておくことがセオリーです。こういったシーンでは定番となっている散布図行列(図4)を用いることで、各変数の分布から2変数間の相関性まで一度に確認することが可能です。
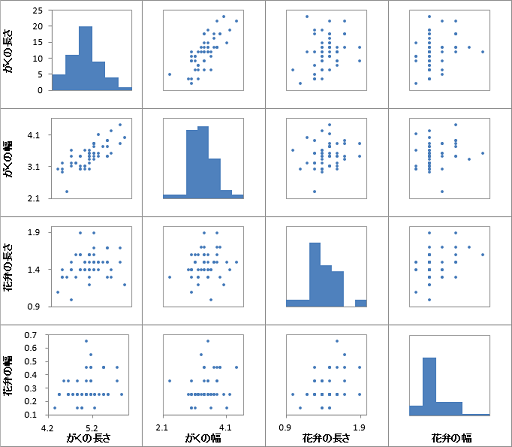
分析の初期段階において、上述したようなデータの代表値や異常値・各変数の分布や相関性の確認を実施しておくことで、後の高度な分析について筋のいい計画を立てることができ、手戻りを減らすことが出来るでしょう。
役割2:新たな仮説(確認すべきこと)を形成すること
仮説には、事前知識から生まれるものと、データに対する洞察をきっかけに生まれるものに大別できると考えています。
前者の具体例としては、対象の系についてのドメイン知識や経験に基づく理解(例えば、中間変数Aが大きいほど目的変数が大きくなるという仮説)や、目的達成の観点で必要な前提(例えば、目的変数の測定精度が十分であるという仮説)といったものが挙げられます。
後者の仮説は、EDAの上述したプロセス(全体像の把握)を行う中で生まれる新たな気付きや疑問により形成されます。製造プロセスのデータに対して一通り可視化を行ったところ100%想像通りだった、などということはよほどなく、何かしら違和感を覚える点があるものです。
例えば、次のような具合です。
- センサー値Aが二峰性の分布になっているのは何故だろうか?
- 制御指示値は一定なのに物性値Aが大きく変動しているのは何故だろうか?
- 不良率を時間帯ごとに求めると差があるのは何故だろうか?
この疑問に対応して、例えば次のような仮説を立てることができます。
- 二交代制で直の違いが出ているから?
- 前工程でのばらつきが影響しているから?
- 不良率に気温の変動が関係しているから?
これこそがEDAの2つ目の役割というわけです。
まとめると、可視化を主体としたEDAを行うことで”データ把握”という全ての分析の土台が整い、その過程で”仮説の形成”が進むことで、その後の分析を効率的に進めることができるという話でした。
仮説の重要性
もし、EDAもほどほどに仮説を立てずに分析を進めるとどうなるでしょうか?仮説なきデータ分析は、砂漠でオアシスを求めて彷徨うようなものだと筆者は感じています。
例えば、100のIoTセンサーを持つプロセスにおいて、”最近歩留まりが低下傾向にあるから、その原因を調べたい”という課題があるとき、仮説が無い場合はどう取り組むでしょうか?とりあえず各センサー値を順番に目視して歩留まりと関係していそうなものを探す…というのは流石に非効率そうですね。では、とりあえず要因分析のために機械学習モデルを組むのはどうでしょうか?多くの場合、精度が出たと思えばデータリークで実地検証したら大外れ、あるいは、精度が出ないため闇雲に精度改善手法を試すも、何が言えるのかはっきりしない分析結果ばかりが増え、分析の方向性が発散し、時間だけが過ぎていく…。データ分析の経験がある方にとってはどこか見覚えのある景色かもしれません。
これとは対照的に、EDAによってデータ理解という土台の上に複数の仮説を形成しておくことができれば、検証すべきポイントを押さえつつ迷いなく分析を進めることができます。
分析のテーマによっては、データの質や量に致命的な問題があり、当初の目的を達成し得ない場合が確実に存在します。そういった場合に、プロジェクトの成否を決める重要な要素となるのが、”データ自体の改善が不可欠”という結論まで素早く説得力を併せて辿り着けること、そして、データの”どの部分をどのように改善する必要があるか”という粒度まで分析結果を落とし込むことです。可視化を用いた適切な仮説検証のサイクルなくして、このような難しさを伴う分析の成功はありません。
本章についてまとめると、
- 可視化の本質は、”数値の図形化”ではなく、”ロジックの見える化”である
- データに対する理解が不足している段階では、EDAという戦略で可視化と仮説の形成を行う
- 仮説があれば分析方針は自ずと定まり、また新たな仮説が生まれるというサイクルに乗れる
という話でした。
データ可視化の戦術
本章では、データを図式で表現するための手段となる”ソフトウェア”と、図の形式である”チャート(chart、graph、plotなど様々な呼称がありますがここではより包括的に使えるchartで統一します)の型”についてまとめてみます。
多くの種類があるソフトウェアについて紹介するために、整理の仕方を考えてみます。分類にあたって次のような観点が考えられますが、明確な線引きが難しいものもあります。
- アプリ型 vs. プログラミングライブラリ型(例:Excel vs. matplotlib)
- インタラクティブ vs. 静的(例:Tableau vs. matplotlib)
- デスクトップ型 vs. クラウド/ウェブ型(例:Tableau Desktop vs. Tableau Online)
- プロプライエタリ(商用など) vs. OSS(Open Source Software)(例:Tableau vs. matplotlib)
これらの分類の組み合わせとして、アプリ型であれば商用製品かつインタラクティブなUIであることが多い、対してプログラミングライブラリ型であればOSSであることが多い、といった傾向があります。これを踏まえ、GUIを有する”アプリケーション”とプログラミングを必要とする”ライブラリ”のどちらの性質が強いかという観点で2つに大別しましたので、それぞれどのようなものがあるか具体的に見ていきましょう。なお、本章の後半では、チャートの型とその選び方について紹介します。
可視化手段①:アプリケーションの紹介
多くの方にとって最も身近なもので言えばおそらくExcelでしょうか。スプレッドシート(表計算ソフト)としての機能に付随するような形で、データの参照範囲とチャートタイプ(棒グラフ等々)を指定することでデータ可視化が行えるアプリには次のようなものがあります。
スプレッドシート系の具体例
- Microsoft Excel:スプレッドシートのデファクトスタンダード。デスクトップアプリとクラウドベース(office365)の両方で提供。マクロ(VBA)を組み合わせれば高度な集計や自動化も可能で、既存の業務フローに組み込みやすい。下記のアプリでもExcel形式のファイルを開くことが出来る。
- Google Sheets:クラウドベースの無料アプリ。
- LibreOffice Calc:OSSであることが特徴のデスクトップアプリ。
- Apple Numbers:デスクトップ版はMac/iOS向け。図表のデザイン性に優れている。
これらのアプリに共通するメリットとして、生の数値が目視によって把握し易いことや、数値の加工を直感的に行えることが挙げられます。ただし、大規模なデータを取り扱うことには適しません。
大規模なデータにも対応できる、より可視化と分析にフォーカスしたアプリとしてBI(Business Intelligence)ツールという概念があります。データ取り込み・集計・可視化・分析をワンストップで行うための機能を備えているため、企業内の多様なデータを統合した視覚的なダッシュボードやレポートを作成することができ、事業上の意思決定にも活用することができる強力なツールです。
BIツール系 (商用製品) の具体例
- Tableau:直感的なドラッグ&ドロップ操作で高度なビジュアル分析が可能。BIツールの代表格であり、このソフトウェア一つで企業価値が1兆円を超えるほど。ライセンス費用はやや高め。
- Microsoft Power BI:マイクロソフト製品(Azure, Office 365など)との連携に強み。無料版があるため導入の敷居が低く、有料版でも比較的コストが抑えやすい。情報も豊富。
- QlikView / Qlik Sense:連想型エンジンによる高速検索・分析が強み。
- Looker:Google Cloudが買収したLooker社が開発。高機能でエンタープライズ用途に特化。
- Looker Studio:クラウドベースの無料アプリ。22年10月に「Google Data Studio」から名称変更。Googleの他サービス(BigQuery等)との連携に強み。
- MicroStrategy:大手企業向けに高度な分析やレポーティングを提供するBIプラットフォーム
- Domo:クラウドBIを主軸に、企業全体のデータを一元管理するプラットフォーム。
- Pentaho:日立が提供する、データ収集から活用までカバーしたOSSのBIプラットフォーム。
そのほかにも、Sisense, Oracle Analytics Cloud, IBM Cognos Analytics, Zoho Analytics, SAS Visual Analyticsなどなど、大変多くのBIツールが存在します。
BIツール系 (OSS) の具体例
- Grafana:時系列データのモニタリングやメトリクス可視化に強いダッシュボードツール。
- Kibana:Elasticsearchの公式フロントエンド。テキスト含むログなどの分析に強み。
- Metabase:シンプルな構成で導入し易いセルフサービスBIツール。有償版もある。
これらを機能的な側面からざっくり分類すると、EDAのような探索的な可視化のし易さを重視しているものと、データベースなどのシステムとの連携を前提としてKPIをモニタリングする用途 (ダッシュボードなど)を重視しているものがあります。
前者は、マウス操作だけでも多様な可視化や分析ができるのでインタラクティブ性に特に優れており、製品によっては、例えば会議中にプレゼン資料とは別にBIツールを用意しておくことで、議論に応じた可視化をリアルタイムで作成し、データ上での仮説検証をその場で回すという使い方さえ可能なほどです。また、グラフを画像として出力するような手段とは異なり、個々のデータ点をマウスオーバーすると追加の情報を参照できる等のメリットもあります。ツールの高機能さに比例して習熟に必要な時間も増加するというジレンマもありますが、ひとたび慣れてしまえば、EDAの効率が段違いに向上するでしょう。
ここまでで取り上げたアプリケーション系のデメリットとしては、そのアプリに搭載されていない機能(マイナーなチャートタイプや複雑な前処理、高度な分析など)は別の手段で行う必要があること、ライセンス料が必要な製品が多いこと、などが挙げられます。
可視化手段②:ライブラリの紹介
もう一方の手段は、ユーザー側でプログラミングを行うことで可視化のライブラリを呼び出すことです。ちなみにライブラリを使わずに可視化を実装するのは極めて非効率です。プログラミング言語の一つであるPythonは可視化ライブラリの充実度が群を抜いているため、ここではPythonで使えるライブラリの中で特に知名度が高いと思われるものを取り上げました。
個々のグラフを作成するライブラリの具体例
- Matplotlib: Pythonのデータ可視化において最も基本的かつ歴史あるライブラリ。多彩なチャート形式に対応しており、グラフの細部まで制御可能な低レベルAPIが充実している。
- Seaborn:統計的な可視化を短いコードで表現でき、スタイリッシュなグラフが作りやすい。内部ではMatplotlibが使われている。Pandasとの親和性が高い。
- Pandas(組み込みのplot機能):pandasの配列インスタンスのメソッド(.plot())により、1行でMatplotlibベースのグラフが出来る。
- Plotly:インタラクティブな操作が可能なグラフを手軽に作成できる。Webブラウザ上で動くダッシュボードへの組み込みも容易。
- Bokeh:インタラクティブな操作が可能なためPlotlyとよく比較される。Webアプリ開発時の柔軟性や大規模データへの対応に強み。
- Altair:宣言的な文法(可視化に含める要素を高レベルで記述)により、簡潔なコードでデータと視覚表現を記述できる。
- ggplot (plotnine): R言語のggplot2を参考に開発されており、こちらも宣言的な文法が特徴。
上記ライブラリとは異なる機能を持つもの
- Dash:上記Plotlyのグラフ等を埋め込んだWebダッシュボードを開発できるフレームワーク。
- Streamlit:データサイエンスの分野と相性が良い、簡単にWebアプリを作れるフレームワーク。
- PyGWalker:JupyterやColab上にGUIが生成され、BIツール感覚で分析できるライブラリ。
これらのライブラリのほとんどはオープンソースとして活発に開発され、仕様や使い方のドキュメントと多くの実装例が公開されており、無料で使用することができます。
ちなみに、データサイエンティストの多くが、無料のBIツールが存在するにも関わらず、可視化のためにコーディングを行ってこれらのライブラリ”も”使用しています。その理由を2つに分けて説明しましょう。
理由1. 全ての分析をPython上で完結させることができるから
多くの場合、可視化するためにはデータの加工が必要です。BIツールでも、任意の粒度で代表値化したり変数間の差分や比率を出すなど基本的な計算を挟むことは可能です。しかし、相関行列やコレログラムといった比較的複雑な演算を行うにはコーディングが避けられない場合が多く、Pythonであれば加工したデータをファイル入出力するまでも無く可視化することができます。また、機械学習において訓練の経過確認や試行錯誤を繰り返す場合に、いちいち外部のアプリを使うという選択肢はまず出てこないことも挙げられます。
理由2:細部のカスタマイズやニッチな形式が実現可能であること
コーディングを必要とするというのは、裏を返せば詳細に設定を記述出来るということでもあります。また、目的に応じて適切なライブラリを選べば、インタラクティブな3Dグラフや、アニメーションを作成することさえも可能であり、望んだ形式が実現できないことの方が珍しいといっても過言ではありません。ライブラリの一つであるMatplotlibのサイトを訪れると、その自由度の高さを伺い知ることができます4。
近年、大規模言語モデル(LLM)の急激な進歩によって、コーディングのハードルやコストが著しく下がっているため、Pythonライブラリを用いた可視化はより一層の広がりを見せるでしょう。
定型チャートの紹介
続いて、”棒グラフ”, ”円グラフ”といったチャートの型について紹介します。Webサイト「The Data Visualization Catalogue」では、非常に多くの種類のチャートが掲載されており、目的ごとに最適なチャートを教えてくれます5。
ここで終わってもいいのですが…、それなりに見覚えのありそうなチャートに絞って以下に書き出してみました。参照文献と同じでは面白くないので、少しひねったカテゴライズにしています。
直交座標系
- 任意の連続的変数が2次元以上:
- 散布図(機能拡張するとバブルチャート), 平行座標プロット, 密度プロット
- 任意の連続的変数が1次元以上:
- 折れ線グラフ, 面グラフ, 棒グラフ(ヒストグラムも含まれる), 箱ひげ図(ローソク足も類型)
- 特有の意味を持つ量的変数を使用するもの:
- 地図(緯度経度), カレンダー(日付)
極座標系
- 円グラフ, レーダーチャート, サンバースト図
- アナログ時計(時刻)
縦軸と横軸の座標が連続的変数と対応しないもの
- ヒートマップ(連続的変数をビン化して使う場合は本質的には直交座標系)
- ツリーマップ, ワードクラウド(各項目の値の大きさに意味があるもの)
- ネットワーク図, 樹形図, フローチャート(関係性に意味があるもの)
- ベン図
名前を知らないものでも、図を見れば”あーこれか”となるものが多いのではないでしょうか。多くの種類があるものの、その大半は連続的”変数”と所定オブジェクトの”座標”とを対応させているというのが本質的なところかと思います。また、オブジェクトの色や大きさと3,4次元目の情報を対応させることで情報量を増やせる場合があります。
チャートの選び方
これだけいろいろなチャートパターンがあることを再認識すると、”どうやってチャートを選べばいいか分からない”という気持ちになるかもしれません。ところが、探索的な分析の観点では、チャートの型選びはそれほど重要な問題ではありません。試しに、全く同じデータを異なる3つのチャート型に当てはめてみましょう。“プロセスインフォマティクスに関する記事に含まれる「単語」と「その頻度」” を仮定して作ったダミーデータで試してみます。
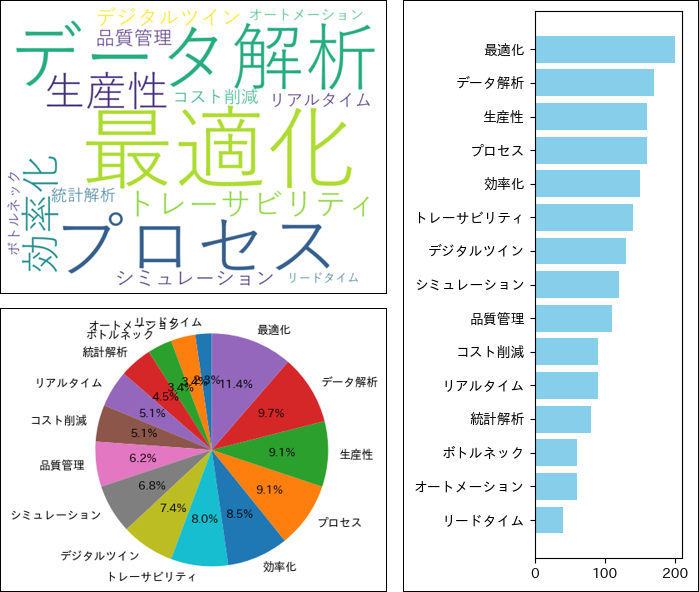
(左上:ワードクラウド,左下:円グラフ,右:棒グラフ)
同じデータとは思えないくらい見た目が違いますね。ワードクラウドは単語の出現頻度を表現する際によく用いられる可視化図法で、ぱっと見ただけで重要な単語が頭に入ってくるというメリットがありそうです。対して、棒グラフは定量的な頻度が、円グラフは全体に対する割合が読み取れるというメリットがありそうです。当たり前ですが、見た目が異なればメリデメも異なるということです。しかし、探索的な可視化という観点で言えば、どのチャートでも基本的な目的(例えば”最適化”や”データ解析”という単語の頻度が高いという気付きを得ること)は達成できるであろうことにも気付きます。
では、重要な傾向さえ汲み取れればどんなチャートを使っても構わないのでしょうか?上で挙げた例と同じデータ形式(カテゴリ×数値)を持つものとして、機械学習モデルにおける”特徴量”とその”寄与度”があります。棒グラフで表現されたそれを筆者は幾度も目にしてきましたが、ワードクラウドや円グラフで表現されたものは一度たりとも見たことがありません。もし見かけたとしたら、”なんでこのチャートにしたんだろう?”と気になって仕方が無くなってしまうと思います。極端な例を挙げれば、反時計回りの時計や直交座標系の時計があったらひどく読みづらいはずです。つまり、説明的な可視化という観点では、慣例があればそれに則ったチャート、特になければより一般的なチャートを用いるのが無難と言えるのではないでしょうか。
以上、可視化の戦術について具体的な固有名詞をこれでもかと取り上げ、全てを把握することの難しさを暗に示しました。しかし、それらの機能にはオーバーラップする部分が非常に多いため、全てを把握する必要はありません。本章が、可視化手段に対する俯瞰的な視点を持つきっかけとなり、適切な手段を見つける際の一助になれば幸いです。
プロセスインフォマティクスを支えるデータ可視化
プロセスインフォマティクス(PI)は、製造プロセスにおける各種の条件パラメータについて、インフォマティクス技術を駆使することでその膨大な組み合わせの中から最適な条件を高速に探索する技術です。一口にPIと言っても、ターゲットとなるプロセスによって、初歩的な要因分析で効果が得られる場合からデジタルツインの構築といった高度な手法が必要となる場合まで適切な進め方は様々です。そのいかなる場合でも必要と言い切れるのが、データ可視化のステップです。まずはその重要性を考えてみます。
プロセスのモデリングにおける重要性
PIでは最適な製造条件を求めるにあたり、対象とする製造プロセスについて数式やシミュレーション、機械学習モデル等を用いたモデリングを行います。分析者が適切なモデリング手法の選択やその設計を行うためには、プロセスデータに対する深い理解が要求されます。
では、そのプロセスデータが取得されるまでには通常どのような経緯があり、どのような関係者がいるでしょうか。以降、量産ラインを前提に例を考えると、データの取得対象を決めた設備設計者に始まり、データの形式を定義したシステム設計者、センサーを開発製造した装置メーカー、それを取り付けた施工業者、維持運用を行う社内システム担当者、キャリブレーションを行う現場担当者、製造条件を制御する現場担当者まで(以降、プロセス関係者と呼ぶ)、異なるタイミングで異なる立場の多くの人間が関与していることでしょう。
果たして、分析者は一部の関係者の断片的な話を聞くだけで、精度の良いモデリングが可能となるほどのデータ理解が得られるでしょうか。ここでは分析者がプロセスデータをより深く理解するために有効と考えられるアプローチを2つ紹介します。
アプローチ1:プロセス関係者が持つ知識を、分析者が能動的にキャッチアップすること
キャッチアップといっても、何も無いところから必要十分な質問を繰り広げるのは容易ではありません。そこで、まずはプロセスデータを丁寧に可視化していき、それぞれについて分析者なりの理解、さらには単なる想像まで含めて詳しく記し、これを関係者に見てもらいながら答え合わせを繰り返すことが有効であると考えています。抽象的に表現するなら、見えているものが異なる人間同士の認識を揃えたいという難題を解決するには、プロセスデータという客観的情報をベースとした議論が有効であり、この文脈においては、データ可視化は共通言語としての役割をも果たしていると言えるでしょう。
アプローチ2:プロセス関係者がデータに対して持っている認識のズレを修正すること
意外に思われるかもしれませんが、プロセス関係者がデータを正確に把握できてるケースは多くありません。少なくとも量産ラインは製品を作るために動いているのであって、データを取るために動いているわけではありませんし、上述したように多くの担当者が関与しているため全てを把握すること自体が難しいのです。したがって、プロセスデータは往々にして多くの問題を抱えており、それは欠損であったり誤差であったり根本的な値の誤りであったりします。こういった問題に気付くことが出来るのがやはり可視化です。Garbage in, garbage outという有名な言葉通り、十分に整えられていないデータでモデリングを行っても望ましい結果は出てきませんから、”急がば可視れ”ということになります。
以上、PIのためにはモデリングが必要、モデリングのためにはデータ理解が必要、データ理解のためには可視化が必要、という話でした。余談ですが、”安定した右肩上がり”だなと感じるグラフがあったとして、それはその人がy=ax+b (a>0)という線形モデルを見出していると言っても過言ではないので、可視化とシンプルなモデリングは紙一重の関係と言えますね。
製造現場でのデータ可視化事例
これまで、一定以上の複雑さを有するデータを扱うのは分析の専門家の役目でした。しかし、データに基づいて実際に意思決定を下すのは、現場の担当者です。近年では、企業内の誰もがデータにアクセスして活用できる環境の構築、即ち”データの民主化”が進んでいます。
工場では、通信技術やセンサー, コンピュータの進化によって、安価かつ小型のデバイスが容易にネットワーク接続できるようになったことでIoT化が進んでいます。製造ラインのデータを詳細かつリアルタイムで取得できることから有効活用できた時の効果は大きく、その活用方法が大きな広がりを見せています。現場におけるデータ可視化も広義のプロセスインフォマティクスと捉え、そのアプローチを3つに大別して取り上げてみます。
アプローチ1:アンドンシステム
“アンドン”は、生産工程の可視化における先駆けと言えるかもしれません。トヨタ生産方式を取り入れた工場では「目で見る管理」が重視されており、その道具の一つであるアンドンは、ラインでの異常発生をランプ点灯で知らせるシンプルなシステムとして始まりました。”andon”はその有用性から、”kaizen”や”kanban”と並び、生産管理の分野では国際的に認知されるに至っており、近年ではIoT技術の活用によってPLCやセンサーから収集したデータに基づいて自動的にアラートを発報したりその対処法も合わせて提示するなどの進化を遂げています。

アンドンシステムの強みは、進化した今もなお一貫している”イベント駆動型のコミュニケーション”にあります。つまり、継続的なデータストリームを表示するのではなく、重大な状態変化や例外事項を強調し、即時の行動を促すことを特徴としており、問題解決プロセスの起点となる重要な役割を担っています。IoT化に伴う進化の例として、Preetam Patilらは、エラーの頻度や時間損失などの⾼度なデータを使⽤することで様々なカテゴリのエラー原因を分析できるスマートエラー検出フレームワークを確⽴し、⽣産性を向上させるスマート組⽴システムを報告しています7。
アプローチ2:デジタルサイネージ
サイネージとは、看板・標識を意味する単語です。ディスプレイなどの電子的な表示機器を使って情報を発信するメディアを総称してデジタルサイネージと呼びます。工場においては、企業から従業員に向けたメッセージに加え、製造ラインの稼働状況や生産進捗といったオペレーションデータを動的に表示するためのツールとして活用されています8。処理端末や大型モニタの価格低下に伴うコスト面での敷居の高さが下がっていることも導入のさらなる追い風となっています。

デジタルサイネージという方法の特徴としては、特定の操作を必要とせず、個々のタスクに集中している作業者に対してもより大きなコンテキストを提供でき、工場全体の目標達成への意識を高める効果が見込める点にあるでしょう。
アプローチ3:対話型ダッシュボード
最後にBIツール等のダッシュボード機能を用いるアプローチについて述べます。上述した方法とは異なり、ユーザーが表示対象をフィルタリングしたり、データをドリルダウンして詳細を確認するといった能動的な可視化が可能です。従来はそういった可視化作業には専門的な知識が要求されましたが、アプリケーションの進化によって現場の担当者や管理者、経営者までもがストレスなく使えるようなインターフェースが構築可能になっています。加えて、任意のデジタル端末で、任意のWebブラウザ(あるいは専用アプリ)でアクセスできる場合が多いです。
ダッシュボードで可視化する対象とその目的を例に挙げれば、生産計画の確認やその計画と実績値の比較、品質指標の傾向把握、設備状態の監視、生産性改善のためのKPI確認、1つの製品の追跡、等々、多岐にわたります。
本章の題目から少し逸れてしまいますが、生産性に関するダッシュボードについて旭鉄工の事例を一つ紹介しましょう。IoTデータは現場の人が見るもので経営者には関係ない、と思っていませんか?IoTモニタリングで収集される各製品の生産数と、予めデータベース化した各製品の付加価値額等を掛け合わせることで、なんとリアルタイムで付加価値生産額が把握できるという、経営者にとっても有益なダッシュボードが作れるのです。
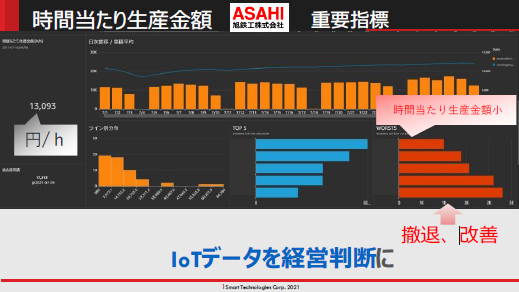
以上、製造の現場においてもデータ可視化が浸透しつつあることについて述べました。こういった可視化を愚直に行い続けることで初めて、見えてくる問題があります。その中で、考え得る要因が多過ぎるなどの理由で人力では解決が困難な課題に遭遇したときに、プロセスインフォマティクスによる要因分析や最適化を適切に用いることができれば、プロセスをより高いレベルへと押し上げることが出来るでしょう。
総括
データ分析では可視化が何より大事なんだ!というスタンスで話を展開してみましたが、いかがでしたでしょうか。データの可視化くらい、Excelなどが使えれば誰でもできるような感覚を持ちがちですが、実は非常に奥深く、分析者の知識や経験,センスが問われる技術であることを感じて頂けたのではないでしょうか。1章目で挙げた例のように、データの背後にある現象を理解していることの重要さと可視化の有用性を心に留めて頂けたらそれだけで十分です。
近年、ますます可視化の手段が豊富かつ手軽になってきている一方で、データ側も何万何億という件数や何百何千という変数を持つようになったり、数値以外の情報が含まれる(マルチモーダル化)するなど、標準的な手段では容易に可視化できないケースも増えています。そういったビッグデータについても、本稿では触れられなかった技術を用いれば処理することができますので、手に負えないプロセスデータがあればぜひ弊社まで。
なお、プロセスインフォマティクスに関する詳細な内容は、弊社の過去のブログでも紹介していますので、興味をお持ちの方は是非こちらのブログもご覧ください。
アイクリスタルはプロセスインフォマティクスのプロフェッショナル集団です。当社の技術やソリューションに関心をお持ちの方は、ぜひ当社のホームページで詳細をご確認ください。
製造業におけるPIの最適なパートナーとして、皆様のご期待に応えます。
お問い合わせはこちら:お問い合わせフォーム
お気軽にご連絡ください。
参考文献
- Edward R. Tufte (1983). The Visual Display of Quantitative Information, https://www.edwardtufte.com/book/the-visual-display-of-quantitative-information/ ↩︎
- Stephen Few (2006). Information Dashboard Design, https://www.academia.edu/1380138/Information_dashboard_design_The_effective_visual_communication_of_data ↩︎
- 散布図行列|統計用語集 – 統計WEB, https://bellcurve.jp/statistics/glossary/5495.html ↩︎
- Examples – Matplotlib documentation, https://matplotlib.org/stable/gallery/index ↩︎
- The Data Visualization Catalogue, https://datavizcatalogue.com/ ↩︎
- トヨタ自動車 75年史 | トヨタ生産方式 | 詳細解説, https://www.toyota.co.jp/jpn/company/history/75years/data/automotive_business/production/system/explanation03.html ↩︎
- P. Patil and G. S. Dhende, “Optimization in MES by implementing smart ANDON system for productivity enhancement,” Int. Res. J. Eng. Technol., vol. 9, no. 2, pp. 936–945, Feb. 2022, https://www.irjet.net/archives/V9/i2/IRJET-V9I2160.pdf ↩︎
- 製造工場のDX進めるデジタルサイネージの活用方法10選, https://yamato-signage.com/factory-digital-signage/ ↩︎
- 製造現場におけるデジタルサイネージの5つのメリット, https://radianttech.net/blog/5-benefits-of-digital-signage-in-the-manufacturing-environment/ ↩︎
- 独立行政法人情報処理推進機構(IPA) 社会基盤センター | 製造分野DX推進ステップ例, https://www.ipa.go.jp/digital/dx/mfg-dx/ug65p90000001kqv-att/000097669.pdf ↩︎
