
本稿では、製造業の現場でしばしば直面する「限られたデータ量」の課題に焦点を当て、スモールデータ環境下でも高信頼性の分析・予測を可能にする考え方と手法を体系的に整理しています。まず第1章では、そもそも「スモールデータ」とは何かを定義し、ビッグデータとの違いや、機械学習の中でスモールデータが担う役割を明らかにします。続く第2章では、ラベル欠如・欠損、クラス不均衡、単純なサンプル不足といった5つの代表的課題を詳述し、これらがプロセス最適化をいかに阻むかを論じます。第3章では、シミュレーションによるデータ拡張、特徴量解析を使った変数選択、そして最新のLLMを活用した文献知識抽出と合成データ生成という3つの実践的アプローチ事例を通じて、課題への具体的な対応策を示します。最終の第4章では、「プロセスインフォマティクスとスモールデータ」と題して、データ量が限られやすい製造現場において、どのようにプロセスインフォマティクスを適用するのかについて、昨今急速に普及が進んでいるマテリアルズインフォマティクスとの違いや、さらには労働人口減少やDX停滞など日本の社会課題に対して、なぜプロセスインフォマティクスが不可欠なのかを通して紹介します。
第1章:”スモールデータ”とは何か?機械学習との関係
製造現場では、設備やプロセスの稼働状況、品質検査の結果など、重要なデータが日々蓄積されています。しかしこれらはしばしば、測定や試験にコストや手間を要するため、収集できるサンプル数が限られてしまいます。限られたデータ量の中で、有用な知見や予測モデルを得るには、単にデータを大量に必要とする従来の機械学習アプローチだけでは不十分です。
そこで注目されるのが「スモールデータ」に特化した機械学習手法です。スモールデータとは、一般に数十~数百件規模のサンプルしかない状況を指し、製造業の多くの現場で頻繁に見られます。こうした環境では、データ不足に起因する過学習や予測不確実性が問題となる一方で、物理知見やドメイン知識を組み込むことで、少ないデータからでも高い説明力と信頼性を兼ね備えたモデルを構築できます。
本章ではまず、スモールデータとビッグデータの違いを整理し、次にスモールデータが機械学習の中でどのような位置づけを持つのかを概観することで、製造現場におけるデータ活用の全体像と、スモールデータへの適切なアプローチを紹介します。
スモールデータ・ビッグデータの違い
製造業の現場においては、装置の稼働ログや品質検査の記録などにおいて、取得できるデータ数が限られている事例が多くあり、これらを「スモールデータ」と呼びます。典型的には数十~数百件のサンプル数であり、取得にコストや時間がかかるデータや、装置の都合でセンサーがつけられない、専門的な測定値、または人的観察データが含まれます。一方で、WebログやIoTセンサーから秒単位で収集される数百万~数億件規模のデータは「ビッグデータ」と呼ばれ、統計的に強力な解析やディープラーニングでの学習が可能です。
スモールデータの特徴は、①サンプル数が少ない、②変数間の相関構造が捉えづらい、③欠損やノイズが相対的に大きく影響しやすい、の3点です。ビッグデータでは、大量のサンプルがモデルの汎化性能を支え、単純な統計学習や深層学習モデルで高い精度を得やすいのが一般的です。一方で、スモールデータにおいては、上記3つの特徴により、単純に大量データ向けの手法を適用しても過学習や不安定な推定結果を招きやすく、慎重な特徴選択やモデル構築が求められます。
製造業におけるプロセスでは、得られるデータがスモールデータであるケースが圧倒的に多いため、「少ないデータでも信頼できる知見を引き出す」ためのアプローチが不可欠です。これが、プロセスインフォマティクスや適応的な特徴重要度評価などの研究が注目を集める背景となっています。
スモールデータは機械学習の中でどういう位置づけか
機械学習は元来、大量のデータからパターンを学習することを得意ですが、先述のように、製造業のように実験や測定にコスト・時間がかかる領域では「スモールデータ」が前提となるケースがほとんどです。ここで重要なのは、データ量が少ない状況下でも以下のような工夫を通じて有用なモデルの構築を目指すという点です。
- 事前知識、ドメイン知識の活用
スモールデータから構築する機械学習モデルに、物理法則やプロセスの知見・ノウハウを組み込むことで、内挿領域に限られますが、取得していないデータ間を補完することが可能です。例えば、ガウス過程回帰(GPR)は、カーネル関数で相関構造を明示し、少数サンプルでも滑らかな予測を可能にします。
- 特徴量選択と正則化
高次元でサンプル数が少ない場合、不要な変数を排除しモデルの複雑さを抑える必要があります。L1正則化やツリーベースの手法(例:LightGBMの特徴重要度評価)を使い、寄与度の低い特徴を除外することによって過学習を防ぎ、より確度の高い機械学習モデルを構築することができます。
- 転移学習・メタ学習
類似プロセスや他プラントのデータを活用して初期モデルを構築し、そのモデルを少量のターゲットデータで適応させることで、短時間で高精度なモデルを構築することができます。このように、既存の知識や学習済みモデルを新たな対象へ引き継いで活用する手法を転移学習と呼びます。
さらに、複数のプラントやプロセスを通じて「少量データから効率的に学習するための学習方法」自体を獲得するアプローチもあり、これはメタ学習と呼ばれます。メタ学習を併用することで、新規現場においても迅速にモデル適応させることが可能となり、これまで十分な知見が存在しない場合においても、比較的高速に高精度な予測モデルを構築することができます。
- 不確実性を考慮したベイズ的アプローチ
ベイズ的アプローチとは、「モデルパラメータは1つの固定値ではなく、ばらつきを持った確率分布として扱う」という考え方に基づく手法です。限られたデータやノイズを含むデータから学習する場合でも、推定結果の不確かさを定量的に評価しながらモデルを構築できます。
このため、単一の予測値だけではなく、予測の信頼区間や発生しうるリスクの大きさを同時に把握することが可能になります。これらの情報は、追加実験の計画立案や運転条件・パラメータ調整の判断材料として活用できます。
これらの手法を組み合わせることによって、スモールデータ環境下でも堅牢かつ説明可能な機械学習システムを構築することを目指していかなければなりません。製造プロセスの最適化には、こうした「少ないデータの中で最も有効な情報を引き出す」機械学習の試行錯誤が不可欠です。
第2章:スモールデータ解析における課題
第2章では、スモールデータ解析において避けて通れない代表的な3つの課題を取り上げます。データ取得にコストや制約がある製造現場では、品質ラベルの欠如やデータの欠損、不均衡なクラス分布、そして単純にサンプル数が足りないといった問題が絡み合い、モデルの精度・信頼性向上を難しくします。本章では、(1)データラベルの不備や欠損がもたらす影響、(2)クラス間の不均衡が招く偏り、(3)単純なデータ不足が引き起こす不安定性に焦点を当て、それぞれの課題の本質と製造プロセス最適化への影響を整理します。
製造現場では、取得したセンサーデータや検査結果のすべてにラベルが付与されているわけではありません。特に大量のログが自動で記録される一方で、実際に品質不良や異常の有無を確認するための人手で付与されるラベルは非常に限定的で、「部分的にラベルがない」データセットや「全くラベルがない」データセットが頻繁に発生します。このようなラベルが欠損しているデータでは、従来の教師あり学習モデルをそのまま適用できないため、データの大半を活かせないばかりか、誤った推定境界を学習してしまうリスクがあります。
一方、欠損データは、センサー故障や測定ミス、運用ミスなどにより、特定の変数値が抜け落ちている状態を指します。欠損が発生すると、サンプルの代表性が低下し、統計解析や行列演算にバイアスが生じやすくなります。特にスモールデータでは、欠損箇所が少数でも全体への影響が大きく、ビッグデータのように他のデータを融合して補うことが難しいため、欠損を含むサンプルを単純に排除すると情報が著しく減少し、逆に不適切な補完を行うと、誤った傾向を導入してしまいます。
さらに、最近の文献では「自動ラベル付与」手法を用いてデータ数を増やすアプローチも報告されていますが、これらはしばしばノイズや誤ラベルを含むため、学習性能を低下させる要因となり得ます。たとえば、文献[2]では自動抽出ツールによるラベルは「ノイズを含む不完全なデータセット」であり、高精度な手動アノテーションと組み合わせないと、モデル評価結果が歪む可能性が指摘されています。
これらのラベル不備・欠損問題は、スモールデータ解析において最初に克服すべき重要課題であり、半教師あり学習やベイズ推定、適切な欠損メカニズムのモデル化など、特殊な手法設計が求められます。
クラス不均衡がもたらす学習バイアス[1]
クラス間の不均衡は、スモールデータ解析において最も頻出かつ重大な課題の一つです。例えば「欠陥品」や「異常プロセス状態」のように発生頻度の低いクラスが全体のごく一部しか占めない場合、モデルは多数派の特徴量を過度に学習し、少数派クラスを正しく検出できなくなる傾向があります。
この問題は、各クラスのデータ占有率
\[ \alpha_i := \frac{N_i}{N_{labeled}} \quad with \quad i \in 1,2,…,K \]
が理想的な一様分布(αi ≈ 1/K)から大きく乖離している場合に顕著となります。このようなデータセットは「クラス不均衡データ」と呼ばれ、学習結果に系統的なバイアスを生じさせます。
製造業のプロセス最適化においては、「異常は稀にしか発生しない」という現実そのものがクラス不均衡の原因となります。その結果、標準的な学習アルゴリズムでは正常データの誤差を小さくすることが優先され、異常状態が見逃されやすくなります。これを放置すると、異常発生時の検知漏れ(False Negative)が増加し、製造ラインの安定運転や製品品質の維持に重大なリスクをもたらします。
このため、スモールデータ環境下では、クラス不均衡の程度を適切に定量化し、その影響を考慮した学習手法や評価指標を導入することが、実務上の重要な課題となります。
以上のように、スモールデータ環境下ではクラス不均衡がもたらすモデルバイアスがそのまま業務上の大きな損失につながるため、この問題を「いかに実務で扱いやすい形で定量化し、緩和策を講じるか」が最優先の課題となります。
単純なデータ不足が引き起こす不安定性
単純なデータ不足は、スモールデータ解析において最も直感的かつ深刻な不安定性を引き起こします。モデル構築に必要な情報が単純に不足しているため、学習アルゴリズムはわずかなサンプルのばらつきや外れ値に過度に影響され、パラメータ推定や予測結果が大きく変動しやすくなります。
例えば、同一のモデル設定であっても、異なるクロスバリデーションの分割やランダムシードのわずかな違いによって、性能評価指標(RMSEや分類精度など)が大きく上下します。これは、学習データの多様性が十分でないために、モデルが特定のサンプル構成に過度に適合し、本来の汎化性能を正しく評価できなくなることが原因です。
また、パラメータ空間が広い複雑モデルほど、少数サンプルでその最適解を探索する際に多峰性の影響を受けやすく、局所解に陥るリスクが高まります。特に、木構造ベースのモデルやニューラルネットワークなど、ハイパーパラメータやネットワーク構造の選択肢が多いアルゴリズムでは、チューニングの度に大きく異なる結果が得られ、製造現場で求められる実務での再現性を担保できません。
さらに、データ不足により事後分布の推定が不安定になるベイズ的手法や、局所的な相関をモデル化するガウス過程回帰などでも、予測区間の幅が極端に広がるケースが見られます。その結果、予測結果をどこまで信頼すべきか判断しづらくなり、現場適用へのハードルが高くなります。
以上のように、スモールデータ環境下ではデータ量の単純不足そのものがモデルの再現性や信頼性を大きく損ない、プロセス最適化のための意思決定を不安定にしてしまうという、避けて通れない課題が存在します。
第3章:スモールデータへの実践的なアプローチ事例
第3章では、スモールデータ環境下でも実際に成果を上げた具体的なアプローチ事例を取り上げます。まず、物理モデルやプロセスシミュレーションを活用して仮想データを生成し、学習データセットを拡張する「シミュレーションによるデータ拡張」を紹介します。次に、限られたサンプル数でも安定した予測性能を得るために、相関解析や特徴重要度評価を駆使してモデルに投入する変数を絞り込む「特徴量解析による変数の選択」の手法を解説します。そして最後に、急速に発展している大規模言語モデル(LLM)を利用して、文献や技術レポートからドメイン知識を抽出し、それをもとに合成データを生成・補完する「LLMによる文献知識抽出とデータ生成」の可能性を探ります。
これら3つのアプローチは、いずれも「データが限られる状況下でいかに信頼性あるモデルを構築するか」という課題に対する異なる解決策を提供します。
シミュレーションによるデータ拡張
製造プロセスの物理法則や設備モデルを用いて仮想的にデータセットを生成し、実測データと組み合わせる手法がシミュレーションによるデータ拡張です。シミュレーションから得られるデータは、実際の計測コストを抑えつつ、多様な運転条件や異常パターンを網羅的に再現できるため、スモールデータ環境での学習モデルに豊富な情報を提供します3 4。
デジタルツインを適用した仮想工場モデルは、センサー情報をフィードバックしながら現実に近いシミュレーションを行い、製造ライン全体の挙動を模擬します。こうしたデジタルツインから生成されたデータは、異常検知や予防保全モデルの学習に活用され、実データだけでは得られない希少な故障シナリオを補完します5。例えばBMWのバーチャルファクトリーでは、Omniverseプラットフォーム上で組み立てラインを再現し、センサー・ロボット動作を含む多様なシナリオをシミュレーションで生成しています6。

また、物理ベースモデルとデータ駆動モデルをハイブリッドに組み合わせることで、シミュレーションの構造的知見と実測データの経験的知見を両立させる手法も報告されています。これにより、少量の実データでもシミュレーション誤差を補正しつつ、高精度な予測性能を達成できることが示されています7。
一方で、シミュレーションと実データのギャップが課題となる場合があります。機械学習モデルが仮想データに過適合し、実環境での汎化性能が低下するリスクを回避するために、Domain Randomizationや物理パラメータの多様化が必要です8。
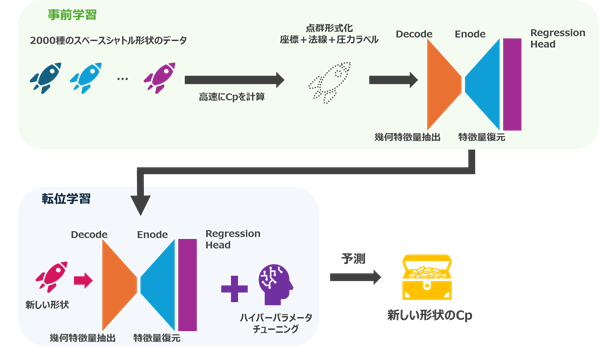
さらに、近年では、シミュレーション精度の異なるデータを組み合わせるマルチフィデリティ学習も研究されていますが、参考文献9のPCDA-TLフレームワークは、異なる発想に基づいています。本手法では、スペースシャトル形状の2,000件の無粘性CFD(Euler)サンプルで事前学習したモデルを基盤とし、Wave rider、Capsule、Slender、Lifting body といった形状の異なる複数のターゲットドメインに対して、各々わずか5~80件のCFDサンプルを用いて転移学習を行います。その結果、各形状における空力特性推定でR²スコア0.822~0.980の高精度を実現しました。つまり、本研究の特徴は、形状の異なる複数モデル間で知識を再利用できる幾何学視点の転移学習にあり、従来のサロゲートモデルが前提としていた「同一のパラメトリゼーションでなければ学習できない」という制約を突破しています。これにより、少数のCFDサンプルからでも新しい機体形状に適応可能であり、設計初期段階における空力予測の大幅な効率化を可能にします。
特徴量解析による変数の選択
小規模データの環境では、観測サンプル数に対して変数の数が多い「高次元かつ小データ」状況が典型的です。不要な変数を取り除き、有意な特徴だけを選択することでモデルの複雑さを抑え、過学習を防ぎつつ解釈性を高めることが重要です。本節では、モデルに組み込まれた手法とモデル非依存の手法、それに中間層の特徴抽出を活用した疑似的変数選択の3つのアプローチを概観します。
単純ベースの組み込み型手法としては、L1正則化を用いたLASSOやElastic Netが古典的です。L1正則化により寄与度の低い変数の係数がゼロに押しつぶされるため、重要な変数を自動的に選択できます。また、ツリーベースのモデル(例:LightGBM)では、学習の過程で各特徴量の分割に寄与した度合いを「特徴重要度」として算出でき、これを閾値でフィルタリングすれば変数選択が可能です[2]。
一方、モデル非依存型の手法では、相関係数や相互情報量などのフィルターメソッド、あるいはSHAP(SHapley Additive exPlanations)やLIME(Local Interpretable Model-agnostic Explanations)といったラッピング手法が用いられます。SHAP値はゲーム理論に基づく各変数の貢献度を示し、サンプル数が少なくても個別予測への影響を定量化できるため、小データ下での安定した特徴ランキングに有効であることが示されています[2]。
さらに、深層モデルの中間層表現を「高次元特徴」の集約版として利用するアプローチもあります。参考文献10では、低忠実度モデルの第一隠れ層に得られる潜在特徴(latent features)が形状や基礎物理特性を捉え、高忠実度モデル学習時にこれらを再利用することで、実データがごく少数でも高精度な予測を可能にすることを報告しています。この手法を応用すれば、元の変数群を直接扱うのではなく、中間層で抽出されたより凝縮された特徴表現を変数として扱うことで、次元削減と情報損失のバランスをとることができます。
これらの手法を適宜組み合わせることで、サンプル数が限られた製造現場のデータでも、ノイズや欠損による不安定性を低減しつつ、重要な要因を明確化したうえでモデル構築を行うことが可能になります。
LLMによる文献知識抽出とデータ生成
LLM(大規模言語モデル)は、文献中に埋もれた知見を自動で抽出し、新たなデータを生成することで、スモールデータ環境下のモデル構築を大きく前進させます。まず、LLMを用いた知識抽出パイプラインでは、数千~数万件におよぶ論文や技術報告書から「プロセスパラメータ」「測定条件」「得られた性能指標」などの構造化情報を、高い精度で抜き出せることが報告されています。例えば、参考文献[2]は、限定的な注釈データしか得られない状況下でも、論文から物性計測値を自動抽出するパイプラインを提案し、わずかなアノテーションで80%を超えるF1スコアを達成していると示しています。
さらに、LLMの生成能力を活かして合成データを生成する手法も注目されています。具体的には、抽出した統計分布や物理制約(例:温度と圧力の関係)をプロンプトとしてLLMに与え、「許容される範囲内のランダムなプロセス条件とそれに対応する性能値」を生成させることで、数十~数百件の実データを数千件規模にまで拡張し、モデルの不確実性を大幅に低減できます。
こうしたLLMベースの文献知識抽出とデータ生成は、ドメイン知識を迅速に取り込みながら訓練データを動的に拡張できるため、スモールデータ解析における最前線のアプローチとして期待されています。
第4章:プロセスインフォマティクスとスモールデータ
第4章では、製造プロセスにおいて、データ量が限られる場合が多いという現実を踏まえ、スモールデータからどのようにプロセスインフォマティクスを構想・設計していくべきか、その考え方と全体像を示します。当社では、従来の工程別最適化を超え、装置稼働データや品質検査、メンテナンス履歴などをデジタルツインに取り込み、仮想空間で高速に最適化を行う統合手法に強みを持っており11、デジタルツインによるプロセス全体最適化で、半導体CISノイズを70%低減させる、30工程を一気通貫したメタファクトリー技術を達成しております12。
本章ではまず、マテリアルズインフォマティクス(MI)との役割分担を整理し、次に労働人口減少や技術伝承の難しさ、DX停滞といった社会課題13 を背景に、プロセスインフォマティクスがもたらす価値を論じ、限られたデータ環境でも効率化と顧客価値最大化を実現する方向性を描きます。
MIとPIの棲み分け
Materials Informatics(MI)は、近年、機械学習を活用した材料開発手法として広く認知され、研究開発から実務応用に至るまで多くの事例が報告されています。材料データを基に、記述子と物性・性能を機械学習でマッピングし、新材料探索や特性予測を行う分野です14。一方、Process Informatics(PI)は「どう作るか」の最適化に焦点を当て、物理シミュレーションやAIを駆使して熱・流体・化学反応など複雑現象を制御可能な条件を導きます。当社では、各工程をデジタルツイン化し連結する統合最適化プラットフォームを構築し、限られた実運転データでも高速に探索・最適化を実現しています。MIが「材料の発見・設計」を担うのに対し、PIは「プロセス条件の最適化」に特化しており、対象とするスケールと領域が異なります。
表 1:MIとPIの比較
| 項目 | Materials Informatics (MI) | Process Informatics (PI) |
| 主な目的 | 新材料の探索・特性予測 | プロセス条件・運転パラメータの最適化 |
| アプローチ | 材料記述子と物性を機械学習でマッピング | 物理シミュレーション・AIで現象を解析 |
| 対象領域 | 材料そのものの設計 | 製造プロセス全体の制御 |
| 活用事例 | 新規材料開発、特性予測 | 最適運転条件探索、異常予知 |
社会課題を踏まえたPIの重要性
日本の製造業は「人口減少」「技能継承の困難」「DX停滞」という三大課題に直面し、生産性・品質競争力維持のボトルネックとなっています。限られた人員・データを最大限活用するPIの導入が急務です。
- 労働力不足:人口は2025年に1億2300万人へ減少し、年間約50万人減少が続いています[14]。2/3の企業が人材不足の影響を受け、人件費高騰や事業継続リスクに直面。さらにIT人材退職による「2025デジタルクリフ」でDX推進の停滞が懸念されています15。
- 技術伝承:熟練者の高齢化・退職により暗黙知の喪失が進み、特に中小企業では教育インフラ不足で技能伝承が滞っています16。
- DX停滞:スマートファクトリー導入は10年進展が限定的で、デジタルツインやAI活用は不十分。調査でも組織体制やリテラシー不足が指摘され17 、品質予測や最適化導入の遅れが競争力低下につながっています。
解決策:プロセスインフォマティクスの重要性
PIはAI・CAE・機械学習を組み合わせ、スモールデータ環境下でも高精度な条件探索を可能にする技術です。当社のメタファクトリーでは企業横断の機密性を維持しつつ、従来の1/1,000の時間で全体最適化を実現しました18。他にもプロセス最適化や運転条件調整、LLMを活用した技術伝承支援などの成果を上げています。
労働力不足への自動化、技能伝承のデジタル化、DX停滞の打破を同時に実現できるPIは、製造業が限られたリソースで顧客価値を最大化するための基盤技術として重要性を増しています。
まとめ
本記事では、製造業における限られたデータ環境下で機械学習を活用するための全体像と具体的手法を示してきました。
- スモールデータの定義と位置づけ
製造現場では、様々な制約によって数十~数百件程度のサンプルしか得られないケースが多く、ビッグデータで用いられる手法をそのまま適用すると、過学習や不安定性を招きやすいことが多いです。そのため、物理知見やドメイン知識を組み込むことで、少量データからでも高い説明力を持つモデルを構築する必要があります。
- 代表的な課題
ラベル不備・欠損データは、半教師あり学習やベイズ推定、適切な欠損メカニズムのモデル化が不可欠であり、クラス不均衡では、異常検知では少数派クラスの検出能力を維持するために、IRやエントロピー指標で定量化し、サンプリングや重み付け手法を導入することが推奨されます。
データ不足による不安定性では、クロスバリデーションやハイパーパラメータ調整の再現性を担保するために、モデル複雑度を制御し、信頼区間を評価することが望ましいです。
- 効果的なアプローチ事例
物理モデルや多忠実度学習で仮想データを生成し、実測データと組み合わせてモデル学習を安定化させる、シミュレーションによるデータ拡張技術が、近年多く研究されています。
特徴量解析による変数選択では、L1正則化、LightGBM特徴重要度、SHAP/LIMEなどを用いて、目的変数の予測にほとんど寄与せず、誤差や過学習の原因となる不要な特徴量を除去することで、モデルの解釈性と汎化性能を向上させることが効果的です。
LLM活用による知識抽出・データ生成も多くの注目を集めています。RAGやプロンプト制御で文献情報を構造化し、合成データを生成することでデータ量を効果的に増強させるアプローチも多く見られます。
- プロセスインフォマティクス(PI)の重要性
製造現場の多様なスモールデータを統合し、デジタルツイン上での最適制御によって労働力不足や技術継承課題、DX停滞といった社会的制約を打破し、生産性と品質の両立を支える基盤技術として今後ますます注目されています。
アイクリスタルはプロセスインフォマティクスのプロフェッショナル集団です。
当社の技術やソリューションに関心をお持ちの方は、ぜひ当社のホームページで詳細をご確認ください。製造業におけるPIの最適なパートナーとして、皆様のご期待に応えます。
お問い合わせはこちら:お問い合わせフォーム
お気軽にご連絡ください。
参考文献
- I. Kraljevski, Y.C. Ju, D. Ivanov, C. Tschöpe, M. Wolff, How to Do Machine Learning with Small Data? — A Review from an Industrial Perspective, (2023). https://doi.org/10.48550/arXiv.2311.07126. ↩︎
- J. Kong, G. Panapitiya, E. Saldanha, Extracting Material Property Measurements from Scientific Literature with Limited Annotations, J. Chem. Inf. Model. 65 (2025) 4906–4917. https://doi.org/10.1021/acs.jcim.4c01352. ↩︎
- K.C. Chan, M. Rabaev, H. Pratama, Generation of synthetic manufacturing datasets for machine learning using discrete-event simulation, Prod. Manuf. Res. 10 (2022) 337–353. https://doi.org/10.1080/21693277.2022.2086642. ↩︎
- V. Buggineni, C. Chen, J. Camelio, Enhancing manufacturing operations with synthetic data: a systematic framework for data generation, accuracy, and utility, Front. Manuf. Technol. 4 (2024). https://doi.org/10.3389/fmtec.2024.1320166. ↩︎
- M. Soori, B. Arezoo, R. Dastres, Digital twin for smart manufacturing, A review, Sustain. Manuf. Serv. Econ. 2 (2023) 100017. https://doi.org/10.1016/j.smse.2023.100017. ↩︎
- BMW’s Virtual Factory Uses AI to Hone the Assembly Line | WIRED, (n.d.). https://www.wired.com/story/bmw-virtual-factory-ai-hone-assembly-line/ (accessed August 8, 2025). ↩︎
- L. Von Krannichfeldt, K. Orehounig, O. Fink, Combining physics-based and data-driven modeling for building energy systems, Appl. Energy 391 (2025) 125853. https://doi.org/10.1016/j.apenergy.2025.125853. ↩︎
- Y. Lu, L. Chen, Y. Zhang, M. Shen, H. Wang, X. Wang, C. van Rechem, T. Fu, W. Wei, Machine Learning for Synthetic Data Generation: A Review, (2025). https://doi.org/10.48550/arXiv.2302.04062. ↩︎
- Y. Shen, H. Zhang, W. Huang, C. Liu, Z. Wang, Geometric-perspective transfer learning for fast aerodynamic prediction in few-shot tasks, Phys. Rev. Fluids 9 (2024) 104101. https://doi.org/10.1103/PhysRevFluids.9.104101. ↩︎
- B.Y.J. Wong, B.C. Khoo, Inductive transfer-learning of high-fidelity aerodynamics from inviscid panel methods, Adv. Aerodyn. 7 (2025). https://doi.org/10.1186/s42774-024-00186-0. ↩︎
- 【プロセスインフォマティクス入門】製造プロセス最適化のための情報技術を易しく解説, アイクリスタル株式会社 (2025). https://aixtal.com/process-informatics/ (accessed August 8, 2025). ↩︎
- デジタルツインによるプロセス全体最適化で半導体CISノイズ70%低減!, アイクリスタル株式会社 (2025). https://aixtal.com/news/20250905metafactory/ (accessed December 12, 2025). ↩︎
- Future Predictions 2040 in Japan, (2022). https://www.works-i.com/english/item/FuturePredictions2040_JP.pdf. ↩︎
- Y.K. Kayla L., How Japan’s declining population is creating opportunities for the future of its workforce, The International (n.d.). https://isshinternational.org/11206/features/tri-school-features/how-japans-declining-population-is-creating-opportunities-for-the-future-of-its-workforce/ (accessed August 8, 2025). ↩︎
- Japan firms face serious labour crunch from aging population, survey shows | Reuters, (n.d.). https://www.reuters.com/sustainability/sustainable-finance-reporting/japan-firms-face-serious-labour-crunch-aging-population-survey-shows-2025-01-15/ (accessed August 8, 2025). ↩︎
- Japan’s succession problem: how the country is safeguarding heritage through business, World Econ. Forum (2025). https://www.weforum.org/stories/2025/04/japan-business-succession-traditional/ (accessed August 8, 2025). ↩︎
- Current Status of Japan’s DX/GX Policies and Company Activities for Their Simultaneous Promotion | Research, Tokyo Found. (n.d.). https://www.tokyofoundation.org/research/detail.php?id=967 (accessed August 8, 2025). ↩︎
- 半導体の製造プロセスを”一気通貫”で最適化! AI活用により企業の壁を越えスピーディな性能改善に貢献, アイクリスタル株式会社 (2025). https://aixtal.com/news/20250325nedo/ (accessed August 8, 2025). ↩︎
